LSbM-tree
2022-11-22|2023-2-10
DieInADream
type
status
date
slug
summary
tags
category
icon
password
Property
Feb 10, 2023 09:12 AM
- ICDCS’17 LSbM-tree: Re-enabling Buffer Caching in Data Management for Mixed Reads and Writes
- TOS’18 A Low-cost Disk Solution Enabling LSM-tree to Achieve High Performance for Mixed Read/Write Workloads
TLDR
- LSM Tree 和 Compaction Buffer 的两个磁盘结构,利用 Compaction Buffer 来延缓缓存的失效
- Compaction Buffer 自带剪枝的机制,有单独的线程检测对应缓存的数据是否还热,不热了就会淘汰,节省存储空间
- 一定程度缓解了块缓存的失效,但是本质没有解决,而且引入了磁盘空间放大,特别是在倾斜负载,即有重复数据写入的情况下。
Abstract
- 因为 LSM Compaction 对 Buffer Cache 的干扰,数据访问可能经历严重的长尾延迟和低吞吐。Compaction 之后数据块被重新组织并写到磁盘上的其他位置,因此被加载到了 Buffer Cache 的相关数据块就会因为引用地址的变化而失效,造成很严重的性能降级。
- LSbM 设计了一个磁盘上的 compaction buffer,来减少 compaction 造成的 buffer cache 失效的情况。compaction 缓冲区有效地、自适应地维护频繁访问的数据集。在LSbM中,强局部性对象可以有效地保存在 buffer cache 中,而不会造成有害的失效。在一个小型磁盘 compaction 缓冲区的帮助下,LSbM 通过启用有效的 buffer cache 实现了高查询性能,同时保留了 LSM 树用于写密集型数据处理的所有优点,并为范围查询提供了高带宽。提升了大约 2x 的性能。
Introduction
- 在 LSM-tree 的原始设计中,没有考虑对缓冲缓存的影响。在 LSM 树存储环境中,可以使用两种类型的 buffer cache 来缓存经常访问的数据: OS 缓冲区缓存 和 DB 缓冲区缓存。
- 操作系统缓存 和 DB 缓存中缓存的数据块直接被索引到磁盘上的数据源。
- 然而,操作系统缓冲区缓存也临时用于缓存 compaction 过程中的数据块读取,而 DB 缓冲区缓存不是。
- 当操作系统缓存被使用时,所有执行查询和 compaction 请求的数据都将临时存储在其中。由于操作系统缓冲区缓存的容量有限,查询请求的数据可能会被 compaction 加载的数据块不断地逐出。因此,compaction 操作可能会导致操作系统缓冲区缓存的容量丢失。
- 为了避免这些干扰,一个基于 LSM 树的数据库实现了一个应用级 DB 缓冲区缓存,只服务于查询。但是,在 DB buffer 中缓存的数据也可能被压缩置为无效。
- 压缩操作经常重新组织存储在磁盘上的数据对象,并更改许多数据对象的映射索引,包括 DB 缓冲区缓存中的数据对象。因此,DB 缓冲区缓存中受影响的数据对象会失效,这称为 LSM 树压缩导致的缓存失效,这将导致 DB 缓冲区缓存的高 miss 率,这是一个结构问题。
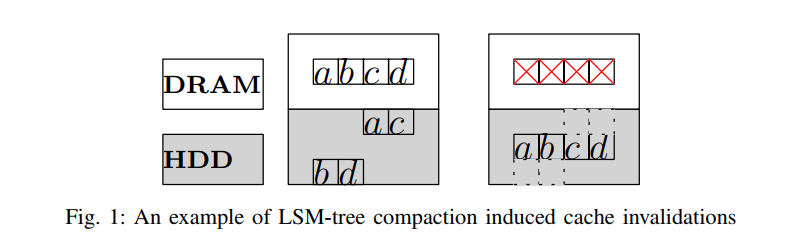
- 如图 1 中的示例所示,a、b、c 和 d 是经常请求的对象,它们属于存储在磁盘上的两个 LSM 级别。最初,包含这些对象的磁盘块保存在 DB 缓冲区缓存中。但是,当LSM-tree 将这两个级别压缩为单个级别时,压缩后的数据将写入磁盘上的新位置。因此,即使这些对象的内容保持不变,这些对象的数据块必须失效,因为底层磁盘数据块已被移动。当再次请求这些对象时,系统必须从磁盘加载包含这些对象的新数据块。随着引用地址的改变,这些对象的访问信息也会丢失。
- 更糟糕的是,由于压缩写是在批处理模式下进行的,对于具有高空间局部性的工作负载,相应的 DB 缓冲区缓存失效和数据重新加载会突然发生,导致显著的性能波动。
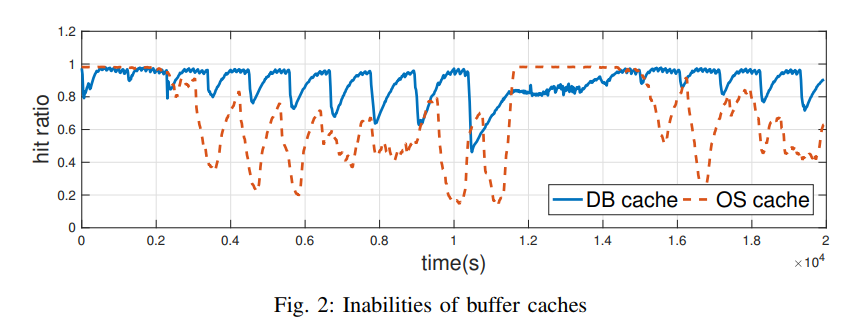
- 我们已经进行了两个测试,以演示 LSM 树上两个缓冲缓存的失效。每个测试的读/写工作负载以及实验设置将在第六节中详细介绍。图 2 显示了同时进行读和写的工作负载的缓冲区缓存(竖条)随时间推移的命中率(横条)。
- 当只使用 OS buffer cache 时(虚线),命中率会周期性地上升和下降。当对频繁访问的数据块进行压缩时,数据被预取到内存中,命中率提高。然而,这些预取的数据会被不经常访问的数据块进行的压缩不断地逐出。
- 当使用 DB 缓冲区缓存时,命中率也会周期性地上升和下降。缓存在 DB buffer cache 中的频繁访问的数据块失效,原因是磁盘上的数据块被压缩重新组织。
- 实验环境:
- LevelDB 1.15
- 8GB DRAM, DB buffer cache 6GB
- level 0 100MB, size ratio = 10, SST size 2MB, block 4KB, BF 15bit/element
- KV pair Size 1KB, DB Size 20GB
- HotRange 98% request 3GB
现有方案
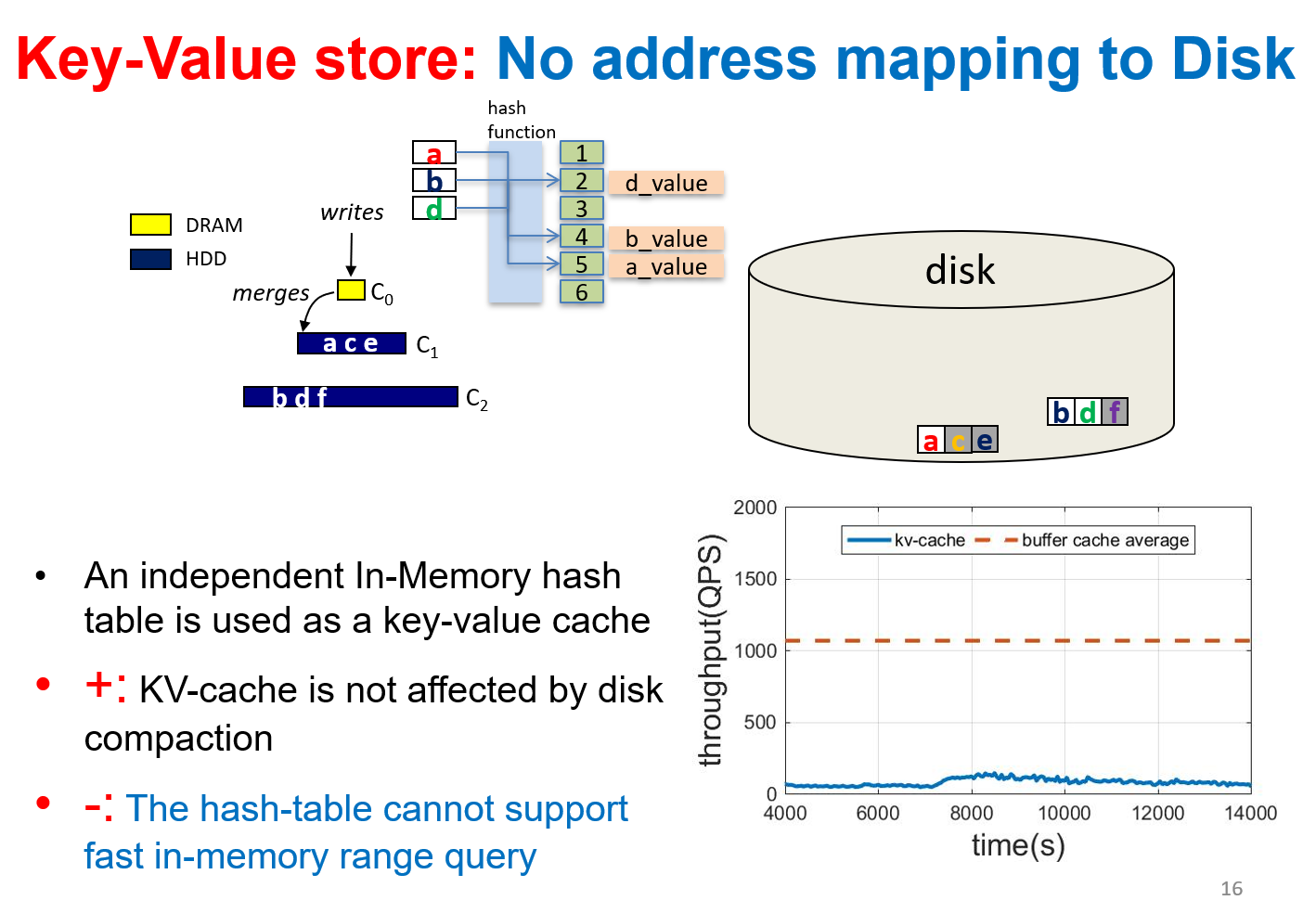
- KV Cache:这个解决方案是在 LSM 树 【Cassandra】之上在 DRAM 中构建一个键值存储。通常,Key-Value 存储缓存是内存中的一个独立缓冲区,不需要对磁盘上的数据源进行任何地址索引。对于读访问,它首先检查键值存储,并希望对命中进行快速访问。否则,它将检查 LSM-tree,并从缓冲区缓存或磁盘检索数据。这种方法将减少对缓冲区缓存的访问,甚至绕过它。不会受到频繁的 Compaction 操作的干扰
- 然而,键值存储对于范围查询和访问具有高空间局部性的数据并不有效,这是由于它的随机存储特性和随机访问的高效率。
- 即使一些键值存储数据结构,如跳表或 B+ 树支持范围查询,磁盘上的数据仍然需要加载,因为内存中的键值存储缓存可能只包含部分数据集,并且它独立于磁盘上的数据结构
- E.g. raw cache in Cassandra, RocksDB, Mega-KV(VLDB 2015)

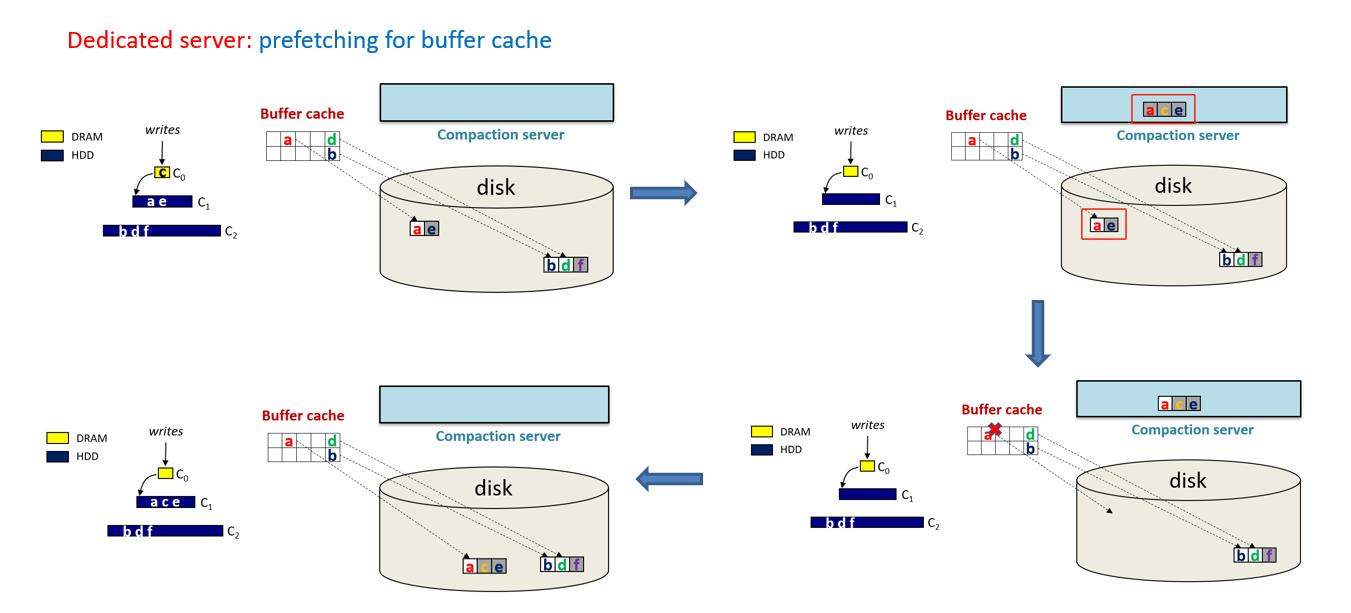
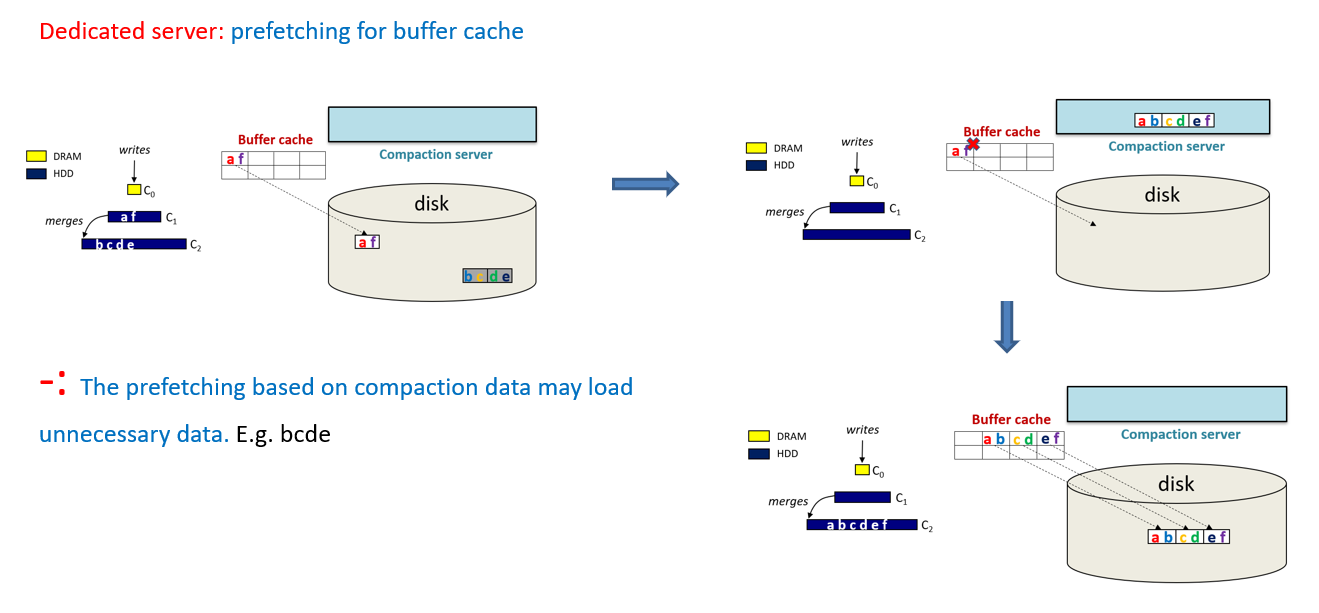
- Dedicated compaction servers:这种方法是使用专用服务器进行压缩,压缩后的数据集保存在这些服务器的内存中,使用增量预热算法[7]替换用户缓冲区缓存中的数据集。这种方法试图通过以这种方式预热缓冲区缓存来减少由 LSM 树引起的未命中。专用服务器方法的有效性取决于识别具有高局部性的特定压缩数据集的能力。它基于这样一个假设:如果新压缩的数据集与缓冲区缓存中的数据共享公共键范围,那么它们将显示高局部性的数据访问。通过实验,我们发现这种假设可能不适用于某些工作负载(即并非所有读取操作都是针对热数据范围的负载),因此,这种方法可能并不总是有效的。
- 说人话就是增量预热算法需要对应正在执行 Compaction 的数据和缓存在 Block Cache 中的数据的范围是相同或者相近的,才有可能有用,而且需要这个范围的数据后续有访问的需求,才会比较有用,因为只是基于简单的范围匹配来实现的,范围可能相同,但数据不一定热。
- E.g. Compaction Management in distributed key-value stores (VLDB'2015)
- 增量预热缓存算法 优点在于可以把 Compaction 生成的新数据根据重叠的键范围来替换掉 BlockCache 中即将失效的数据,从而来避免失效
- 增量预热缓存算法 缺点在于简单的键范围重叠可能会加载一些并不是很热的数据到缓存中,造成了缓存空间的浪费。

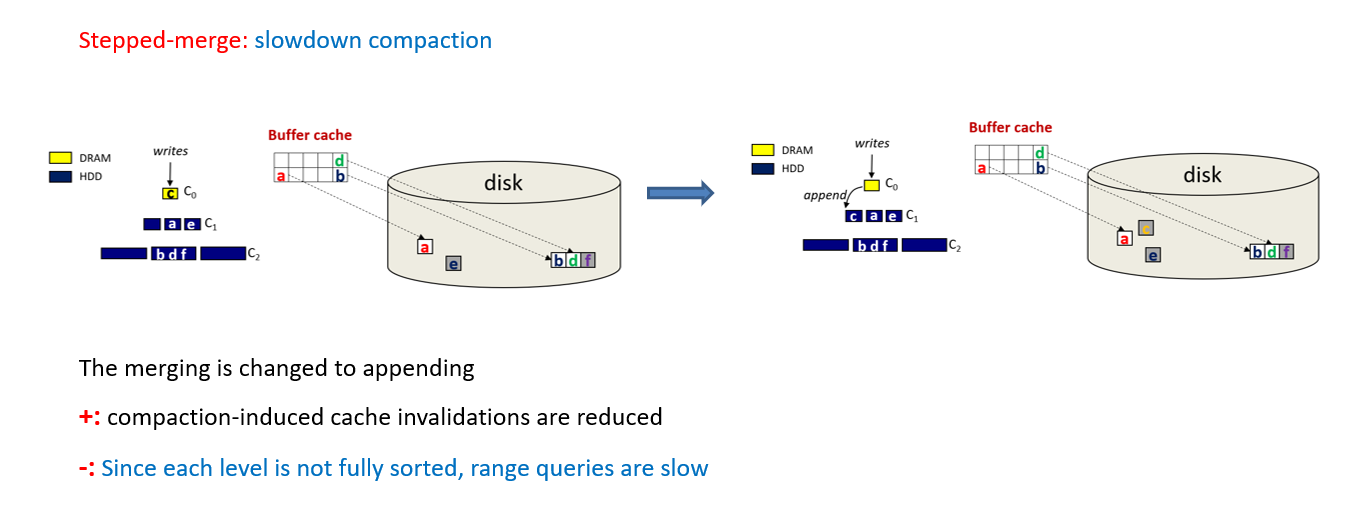
- Stepped-Merge algorithm (SM-tree in short):该算法是为了平衡数据仓库压缩 I/O 和搜索成本之间的平衡而提出的。与 LSM 树类似,SM 还将数据组织成大小呈指数增长的多级结构,并使用顺序的 I/O 压缩数据。但是,一层中的数据对象并不是完全排序的,只有当它们被移到下一层时才被读取和排序。因此,压缩的数量和缓存失效的速度可能显著降低。但是,SM-tree可能会从两个方面降低查询性能。首先,每一层的数据没有完全排序。因此,SM 的范围查询性能较低。其次,对于有大量重复数据的工作负载,整个数据库的大小可能会变得不必要的大,因为过时的数据不能被及时的压缩丢弃。
- 说人话,就是 Tiered Layout
- E.g. VLDB'1997 Incremental Organization for Data Recording and Warehousing

- 我们工作的目标是 最好地利用缓冲区缓存来快速随机访问和范围查询,并最好地利用磁盘的优点来长时间连续访问范围查询。这些目标应该在基本的lsm树结构下实现。
Our Solution
- 在本文中,我们提出了日志结构的缓冲合并树(lsbm-tree 或简称 lsbm),这是一种高效、低成本的lsm树变体,具有一种新的缓冲合并压缩方法。对于读和写密集的工作负载(本文中提到的术语缓冲区缓存指的是DB缓冲区缓存),LSbM 通过在DB缓冲区缓存中保留位置提高了整体查询性能。LSbM 的基本思想是添加磁盘上的 Compaction 缓冲区,以最小化压缩导致的频繁缓存失效。Compaction 缓冲区直接映射到缓冲区缓存,并在底层 LSM 树中维护经常访问的数据,但更新的速率比压缩速率低得多。LSbM 将查询定向到缓冲缓存中经常访问的数据的 Compaction 缓冲区,并将查询定向到底层 LSM 树,用于其他查询,包括长距离查询。简而言之,使用较小的磁盘空间作为 compaction 缓冲区,通过使用有效的缓冲区缓存为频繁的数据访问提供服务,LSM 3实现了高而稳定的查询性能,同时对写密集型的工作负载保留了lsm树的所有优点。
- 我们已经实现了一个基于LevelDB(谷歌开发的广泛使用的lsm树库)的lsbm原型,并与Yahoo!云服务基准(YCSB)。我们证明,使用标准的 Buffer 缓存和硬盘存储,我们的LSbM 实现可以比LevelDB实现2倍的性能提升,并且显著优于其他现有解决方案。
Design
- LSM-tree 中对 Buffer Cache 的压缩干扰是由磁盘上缓存对象的重新寻址引起的。考虑到这个问题的根源,我们的目标是控制和管理 LSM-tree 的动态压缩。理想情况下,压缩对缓冲缓存造成的负面影响可以以非常低的成本最小化。
- 在介绍 lsbm 如何有效地防止缓冲区缓存因压缩而失效之前,让我们考虑一下为什么 LSM-tree 需要在每一层上维护一个已排序的结构。在 LSM 树中,任何查询都将逐层执行。同一 Key 可能存在不同级别的多个版本,其中只有最新版本有效。由于上层包含最近的数据,所以查询是从上层向下层执行的。每一层的数据可能属于一个或多个已排序的表。这些已排序表的键范围可能相互重叠,因此需要分别检查。对于随机数据访问,一旦找到匹配的键,将立即返回数据对象。即使 bloom 过滤器可以帮助避免不必要的块访问,但当每一层已排序表的数量增加时,检查 bloom 过滤器和读取由假 bloom 过滤器测试引起的假块的开销就会变得非常大。对于范围查询,将搜索所有已排序的表,并读取所请求的键范围覆盖的所有数据对象,并合并在一起作为最终结果。查询一个级别的多个排序表可能需要多个磁盘搜索。因此,需要限制每一层中已排序的表的数量。
- 在高有序性和低有序性之间有一个权衡。查询可以从 LSM 树级别的完全排序结构中受益,但是,维护这样一个完全排序的结构需要频繁地执行压缩,这可能会使缓存的数据对象无效。这种权衡促使我们找到一种方法来维护 LSM 树的完整排序结构,同时防止缓冲区缓存因压缩而失效。
- 我们设计的基本思想是在磁盘上保存两个数据结构。一个数据结构包含整个数据集,每一层的数据都按照传统的 LSM 树完全排序。我们称它为底层 LSM 树。另一种数据结构只包含经常访问的数据,其中的数据不经常通过压缩更新。我们称之为压缩缓冲区 Compaction Buffer。
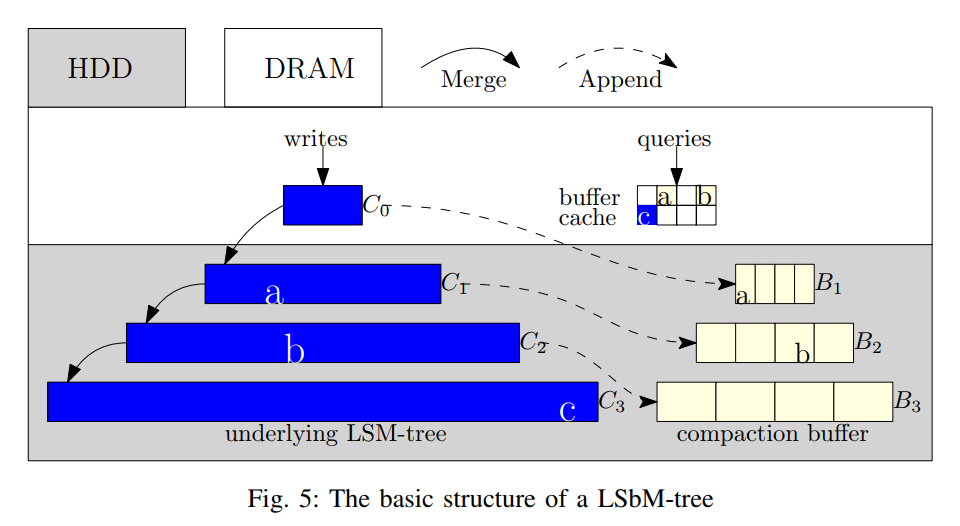
- 将第 i 级的压缩缓冲表表示为 ,将 中的第 j 个排序表表示为 。 包含 中最新的数据。图 5 显示了一个包含三个压缩缓冲区列表的压缩缓冲区。 (1 <= i <= 3) 包含 i 级频繁访问的数据集,但更新速度非常低,以保证缓存数据的有效性。
- 在 LSbM 的 i 级中,对于经常访问的数据(在缓冲缓存中很可能被命中),读请求被分派给 ,对于其他数据则被分派给 。如图 5 所示,请求对象 a、b 和 c。其中 a 和 b 从 buffer cache 中读取,因为分别在 和 中被索引。对象 c 是从底层 LSM 树的 加载的。
COMPACTION BUFFER
- 压缩缓冲区只维护频繁访问的数据,而压缩并不经常更新这些数据。因此,压缩缓冲区需要能够有选择地只保留经常访问的数据,并保持它们的稳定性。在本节中,我们将介绍与 LSM-tree 相关联的缓冲合并算法,以便为压缩缓冲区准备数据,以及在压缩缓冲区中只保留经常访问的数据的修剪过程。压缩缓冲区使用的磁盘空间是有限的,并且压缩缓冲区的构造没有额外的 I/O 成本。接下来,我们将介绍构建压缩缓冲区的详细操作。
Buffered merge
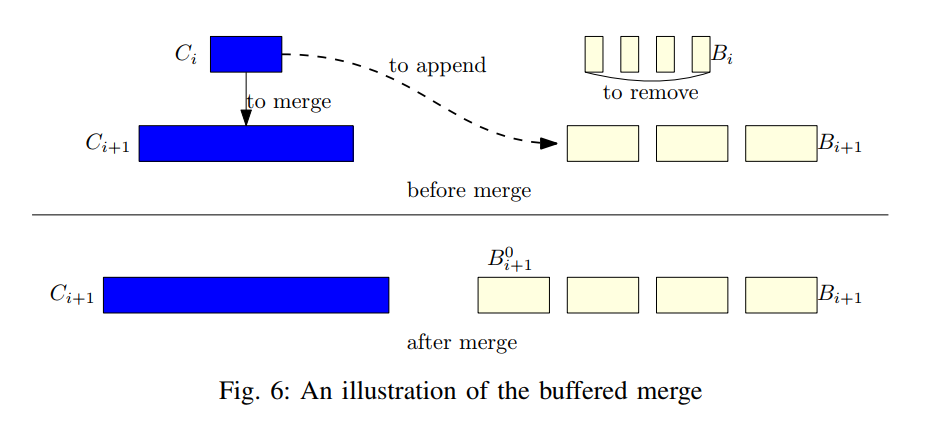
- 图 6 展示了缓冲合并的工作原理。当 满时,它的所有数据将通过归并排序合并到 中。同时,它也会以 的形式加入到 中。注意, 是用已经存在于磁盘上的 文件构建的。因此,不涉及额外的 I/O。 中之前在 中的数据不会被压缩更新。此外, 包含 中的所有数据,但是完全排序的,因此与 相比,它是更好的查询候选对象。因此, 中已排序的表变得不需要了,它将从压缩缓冲区中删除,然后从磁盘中删除。
- 当一大块重复数据被写入 i+1 级时,压缩会丢弃 中相同数量的过时数据(因为合并)。然而, 中这些数据的对应项也会过时,但不能丢弃,因为压缩缓冲区中的数据一旦添加就不会被压缩。那些过时的数据会占用额外的磁盘和内存空间。因此,压缩缓冲区列表不适用于插入重复数据的 levels。
- 在 LSbM 中,通过比较压缩到 的数据的大小与 本身的大小,可以很容易地检测出 i+1 级重复数据的存在。如果 的大小小于压缩到其中的数据,则必然存在重复数据(Compaction 的输出数据量小于了输入的数据量)。当检测到重复数据时,LSbM 冻结 。当 已满并被合并到下一层时, 将被解冻,并继续作为 的压缩缓冲区列表。
- 这里其实是一个先后顺序的问题,即把数据加到 Disk Buffer Cache 和 Compaction 到下一层的先后顺序:为了保证后续的读取操作的正确性,更新的数据应该来处理读请求
- 使用缓冲合并,在 i 级上创建了两个数据结构: 和 。 中的数据是完全排序的,但经常通过压缩更新,而 中的数据不经常更新,但没有完全排序。在 中,经常访问的数据块直接被索引,不频繁的更新可以防止缓存中的数据块失效。通过这种方式,压缩缓冲区充当缓冲区,以隐藏在底层 LSM 树上执行压缩所导致的严重缓冲区缓存失效。这导致了它的名称,压缩缓冲区,以及合并算法的名称,buffered 合并算法。
- 当 满并合并到 时, 中的数据被删除, 服务的读取被转移到 。注意, 包含经常访问的数据,它的大部分数据块都被加载到缓冲区缓存中。突然删除 将会导致命中率大幅下降和性能下降。为了减缓传输过程,我们开发了与 bLSM-tree 的齿轮调度合并算法[13]相关联的缓冲合并算法。
- 在 bLSM 中,i 级数据(0 <= i < k)属于两个排序表, 和 。当 满时,它的数据将被移动到 ,并开始合并到 。同时, 变为空,并继续接收从第 i-1 层的数据。在每一层中,bLSM 定义了 和 两个参数来规范数据合并到 和数据移出 的过程。为了简单起见,我们简化了这个规则,将 和 的总大小固定为常数,即 i 级的最大大小 。
- 如图 7 左侧所示,当将数据块压缩到 中时, 中相同数量的数据被压缩到 中。因此,当 满时, 必须为空, 中的数据可以移动到 并重新开始。在这种设计中,一层上的压缩由其上一层的压缩驱动,最终由写缓冲区 上的插入操作驱动。因此,数据可以以可预测的延迟插入 。
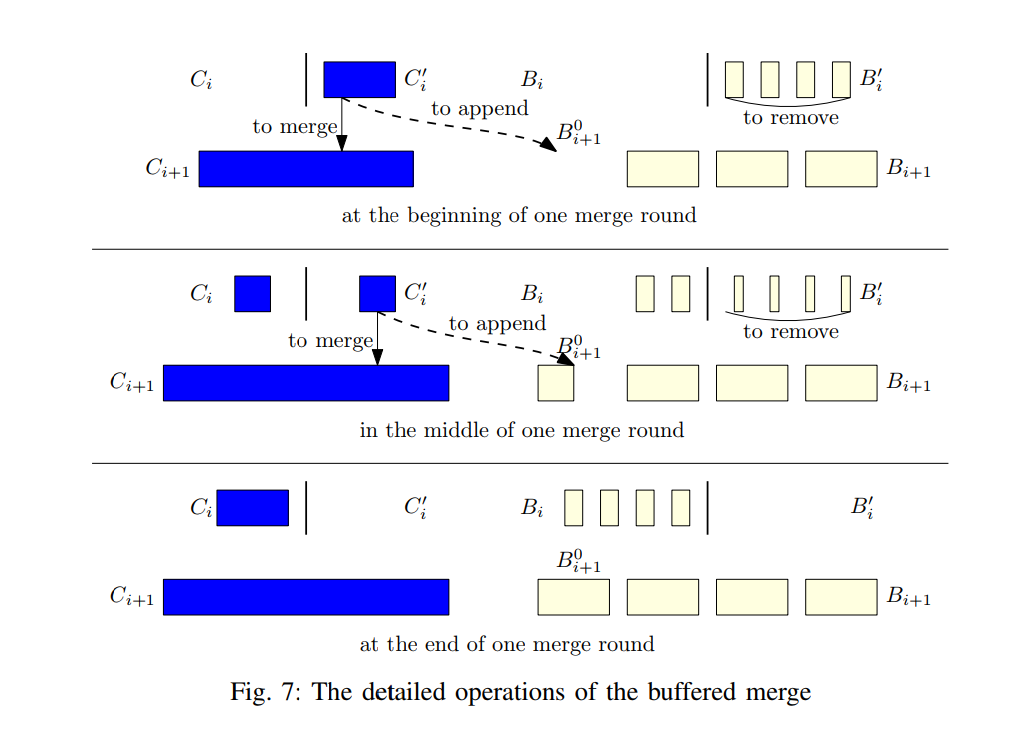
- 我们在缓冲合并操作中采用了这种合并算法。如图 7 所示,第 i 层的 Compaction Buffer 也划分成了两部分, 和 。
- 算法 1 描述了基于 bLSM-tree 合并算法的缓冲合并算法。与 bLSM-tree 合并相比,缓冲合并的附加操作用粗体突出显示。
- 一个压缩线程监视 Level 0 的大小,数据由另一个线程插入到 C0 中。一旦 Level 0 的总大小达到 L0 的大小限制 S0,那么就触发 Compaction。
- Compaction 一级一级执行,直到最后一层,或者遇到一个没满的层次(代码 5-6),对于一个特别的层次 i,如果 为空,数据将从 移动到 ,同时在 中的数据也被移动到 (代码 8-9)。这些数据移动不需要任何 I/O 操作,只有索引的修改。注意 只包含了 level i 频繁访问的数据,因此 的大小是一个变量,通常小于 ,另外一个参数 被用来记录 的大小(当数据初始被移动到其中时)。
- 一个空的有序表 是在 中创建的,并接收来自 的数据。在所有的操作之后, 肯定是不为空的,那么就从 中选出一个文件 ,然后这个文件 通过归并排序被合并到了 (代码 12-16),基本的 Compaction 单元对于不同的 LSM 实现也是不同的,所以我们继承了 LevelDB,在每次 Compaction 中合并一个文件到下层,不再直接删除文件,而是将 追加到 ,从 移除数据的节奏和从 中移除数据的节奏一致,换句话说, 和 在整个合并过程中是相等的
- 为了实现这个效果, 在每次 Compaction 之后移除具有最小的最大键的文件,从而移除 中相同比例的数据。与底层的 LSM 树不同,从压缩缓冲区中删除文件具有不同的含义。从压缩缓冲区中删除的文件将被标记为删除。除最小和最大键外的所有索引将从内存中删除,其所有数据将从磁盘中删除。这是专门为查询正确性而设计的,将在第五节中讨论

- 对于缓冲合并,如果所有追加的数据都保存在压缩缓冲区中,整个数据库的大小将增加一倍。此外,如第三节所述,对不经常访问的数据进行查询对搜索的排序表的数量更敏感,因为可能涉及更多的磁盘搜索。因此,那些不经常访问的数据应该从压缩缓冲区中删除。对它们进行的查询应该由底层的 LSM-tree 提供,该树在每一层中包含的排序表要少得多。在下一节中,我们将解释压缩缓冲区如何选择性地只保留经常访问的数据。
Trim the compaction buffer
- 在运行期间,不断评估压缩缓冲区中的数据,以确定它们是否符合保存在压缩缓冲区中的条件。我们称这个过程为修整 Trim 过程。
- 修整过程的基本操作单元也是一个文件。算法 2 展示了 LSbM 如何对压缩缓冲区进行修剪,有选择地保留其中包含频繁访问数据的文件
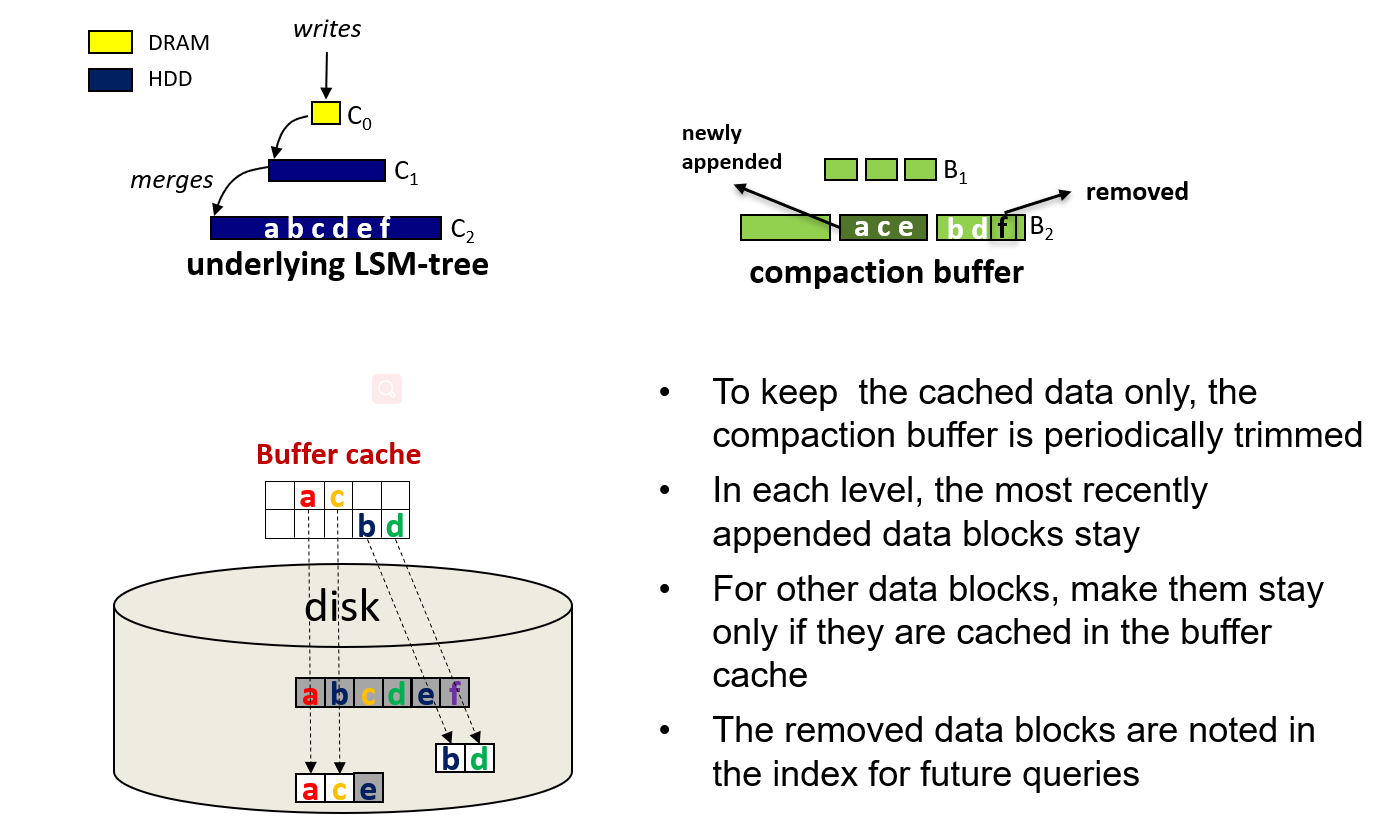
- Compaction buffer 也是逐层进行剪枝的,对于 level i, 是新的追加到 的,它其中频繁访问的数据块仍在积极地加载到缓冲区缓存中,因此不应该修剪。但是其他有序的表需要被剪枝
- 对于 中的每个文件 f,如果该文件不包含经常访问的数据的话将被删除。
- 在 LSbM,一个文件是否包含频繁访问的数据,是由缓冲缓存 buffer cache 中缓存的块的百分比来衡量的。
- 一个文件的缓存块的数量可以通过一个被缓存的整数计数器来收集,一旦它的一个块被加载到缓冲区缓存中,它就会增加,一旦它的一个块被从缓冲区缓存中移除,它就会减少。
- 这些操作轻量,开销小。当缓存块的百分比小于阈值时,这个文件将从压缩缓冲区中删除(第4-7行)。
- 修整过程由一个独立的线程周期性地进行。间隔时间可作为优化参数进行调整。

File Size
- 文件大小无论是对于底层 LSM 还是 Compaction Buffer 而言都是一个很重要的因素,定义了对应的 Compaction 和 Trim 的粒度,如算法1 描述,数据一次只是被压缩到一个文件中。对于文件大小为 s 的文件,将 s 数据从第 i 级压缩到第 i +1 级需要 (r+1)*S/s 的输入操作将数据装入内存,以及 (r+1)*S/s 的输出操作将压缩后的数据写入磁盘。s 越大,I/O 操作次数越少,压缩效率越高。因此,底层 LSM-tree 的文件大小不应该太小。
- 但是,在压缩缓冲区中,由于文件大小较大,导致修剪过程中频繁访问的数据识别精度较低。这是因为键范围较大的文件包含频繁和不频繁访问的数据的可能性更大。此外,压缩缓冲区中原先属于底层 LSM-tree 上层的文件的 key 范围可以比底层 LSM-tree 中同级的文件大 r 倍。正如将在第五节中讨论的那样,从 Bi 中删除一个文件不仅会阻止这个文件,而且还会阻止 Bi 中另一个键范围与被删除文件重叠的 r1 文件用于提供查询。因此,一旦从 Bi 中删除一个文件,对最多 r 个文件进行的查询就可以被重定向。由于这些文件都包含频繁访问的数据,可能会导致性能下降。因此,压缩缓冲区的文件大小不应该太大
- 底层 LSM-tree 和压缩缓冲区需要不同的优化文件大小,但所有压缩缓冲区的文件都是由底层 LSM-tree 创建的。为了解决这个问题,我们在排序表的索引结构中添加了一个额外的层,在排序表层和文件层(超文件)之间。每个超级文件映射到固定数量的连续文件,所有这些文件存储在一个连续的磁盘区域。超级文件是底层 LSM-tree 的基本操作单元,而文件是压缩缓冲区的基本操作单元。通过这种设计,即使压缩缓冲区的所有文件都是由底层 LSM-tree 创建的,这两个数据结构也可以相应地选择它们自己的适当的文件大小。
The effectiveness of the compaction buffer
- 我们在第 VI 节中的实验将表明,压缩缓冲区最小化甚至消除了有害的缓冲区缓存无效。两个原因导致了它的有效性。
- 首先,缓冲区缓存 buffer cache 直接映射到压缩缓冲区 compaction buffer,而不是映射到 LSM-tree,而压缩缓冲区是通过附加操作而不更改数据地址来构建的。因此,与 LSM-tree 相比,压缩缓冲区中的数据更新频率显著降低。
- 其次,当 LSM-tree 的 级别中的数据被合并到下一级别时,压缩缓冲区列表 Bi 可以开始将其上的读取转移到下一级别。为了尽量减少有害的缓存无效的机会,转移是小心而逐步进行的
- 压缩缓冲区还可以适应各种工作负载。
- 对于只进行密集写的工作负载,不会将数据加载到缓冲区缓存 buffer cache 中,压缩缓冲区中所有附加的数据都将被修剪 trim 过程删除。
- 对于只进行密集读的工作负载,压缩缓冲区 Compaction Buffer 是空的,因为只有通过执行压缩才能将数据追加到压缩缓冲区。
- 对于具有密集读和写的工作负载,压缩缓冲区 Compaction Buffer 可以有效地保存在缓冲区缓存 Buffer Cache 中的加载数据,而底层 LSM-tree 保留了传统 LSM-tree 的所有优点
Disk I/O and storage cost
- 构建压缩缓冲区不涉及任何额外的 I/O 操作。如IV-A节所述,用于构建压缩缓冲区的所有文件已经存在于磁盘上。只修改排序表的索引。因此,构建压缩缓冲区的 I/O 成本可以忽略
- 在修剪过程中,所有留在压缩缓冲区 Compaction Buffer 中的文件必须包含在缓冲区缓存 Buffer Cache 中加载的大量数据块。因此,压缩缓冲区 Compaction Buffer 的大小由缓冲区缓存 Buffer Cache 大小和读/写工作负载决定。一般来说,缓冲区缓存 Buffer Cache 的大小和频繁访问的数据是相对较小的。因此,额外的磁盘空间成本低且可接受,这在 vii-e 节的实验中得到了证明
Query Processing
- 在缓冲合并算法中,LSbM 的磁盘数据由两种数据结构组成:底层的LSM-tree包含了整个数据集,而压缩缓冲区只包含了经常访问的数据集。这两种数据结构和谐而有效地工作在一起,为查询提供服务。
- 算法 3 描述了一个随机数据访问的步骤。随机数据访问是逐级进行的。
- 当搜索一个级别 i 带压缩缓冲区列表,Ci 的索引和bloom过滤器将首先检查,以验证这个键是否属于这个级别(行3-10)。
- 如果判断该键不属于 Ci,则无需进一步检查 Bi 中已排序的表,因为它是 Ci 的一个子集。
- 否则,Bi 中已排序的表将一个接一个地被检查(第 12-23 行)。
- 一旦在此过程中遇到键范围覆盖目标键的删除文件,检查 Bi 的操作将立即停止(第15-16行)。这是因为目标键的最新版本可能已经从 Bi 中删除,并且可能会错误地返回一个过时的版本。
- 如果在 Bi 中任何一个已排序的表中找到目标键,则将返回目标键和值(第17-23行)。
- 否则,Ci 中的目标块将被读取并服务于读取(第24-25行)。
- 如果目标键在任何级别都没有找到,则返回not found符号。

- 尽管每个压缩缓冲区列表包含多个排序表,但底层 LSM-tree 的索引和 bloom 过滤器可以帮助跳过不包含目标键的级别。因此,只需要检查可能包含目标键的级别的压缩缓冲区 Compaction Buffer 列表。每个压缩缓冲区列表的排序表的数量从 0 到 r 不等,平均为 r/2,此外,目标键可以在任意 r/2 排序的表中找到,然后返回。因此,在LSbM 中,每次随机访问需要检查的额外排序表的数量大约为 r/4。
- 执行范围查询的步骤在算法 4 中列出。为简单起见,我们假设请求的键范围只能由每个已排序表中的一个文件覆盖。
- 当搜索级别 i 的压缩缓冲区列表,Ci 的索引将首先检查。
- 如果请求的键范围没有与 Ci 中的任何文件重叠,则继续搜索其他级别(第3-5行)。
- 否则,需要首先检查 Bi 中已排序的表。
- 在检查 Bi 中已排序的表时,会维护一个文件队列 F 来记录 Bi 中键范围与所请求的键范围重叠的所有文件(第8-14行)。
- 与随机数据访问类似,一旦发现被删除的文件与请求的键范围重叠(第11-13行),我们将停止检查 Bi 并清除文件队列 F,因为 Bi 可能包含不完整的请求数据。
- 最后,如果检查 Bi 后 F 不为空,将读取 F 文件中请求的数据。
- 否则,从 Ci 读取文件 f 中请求的数据(第15-19行)。

- 这两个算法简化了查询操作,通过假设在 level i 只有 和 ,但是,LSbM 的一层可能包含四个组件,, 、 和 ,对于这个情况, 和 的组合被视为一个整体,因为数据是从 到 流动的,他们的键范围相互补充。而 是这个组合的一个子集,当在 level i 上构建查询的时候, 和它的 compaction buffer list 将被首先查询,然后查询组合 和 ,然后查询
测试
实验设置
- 基于 LevelDB 1.15,对比分段合并 Stepped-Merge 以及 bLSM-tree,还有增量预热方法,以及 KV 缓存
- 硬件环境:8GB 内存,DB Buffer 设置为 6G,剩下的由 SST, BF, OS buffer cache 共享。
- 软件环境:Level0=100MB,size ratio=10,层级 1,2,3的最大大小分别为 1G,10G,100G。文件大小对应 2M,LevelDB 默认值。定义一个超级文件对应包含 r 个小文件,r=10,那么超级文件的大小为 20MB,块大小设置为 4KB,等于磁盘页大小。BF 的位数为 15,键值对 1KB。Trim 间隔时间 30s,只有当一个文件的 80% 的块被缓存到缓冲区缓存中时,它才能被保存在压缩缓冲区中
- 测试命中率和 Cache 的使用率
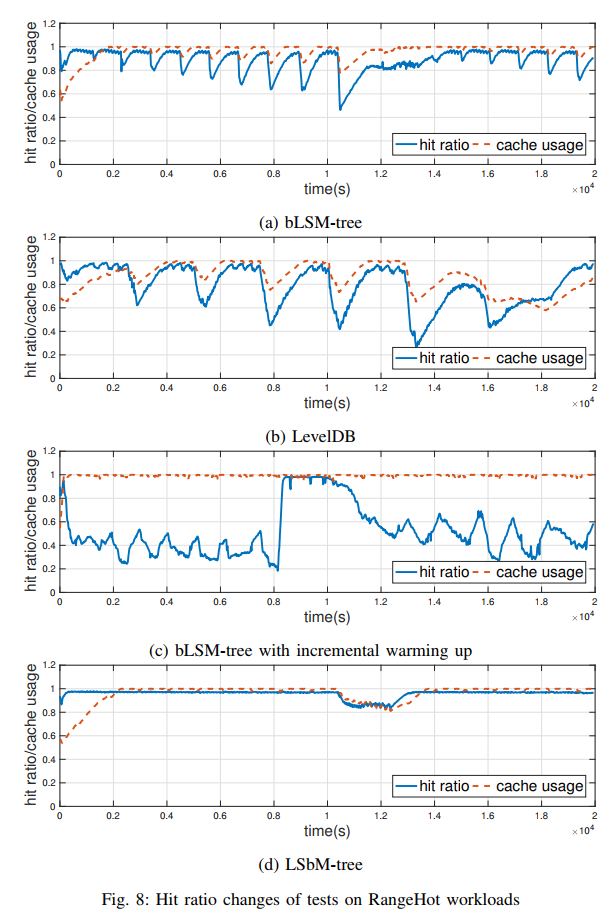
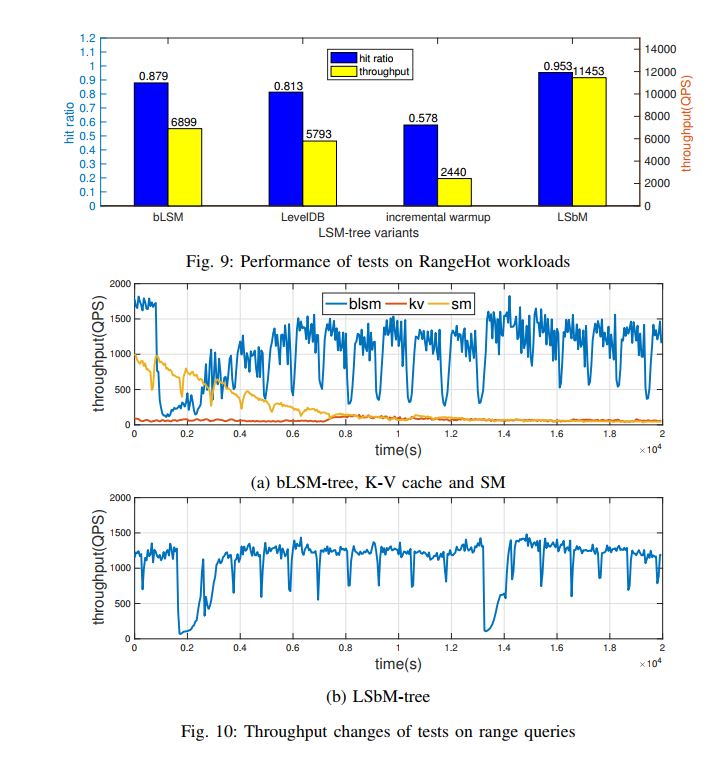
- 测试在 RangeHot 负载下的性能以及测试范围查询下的性能

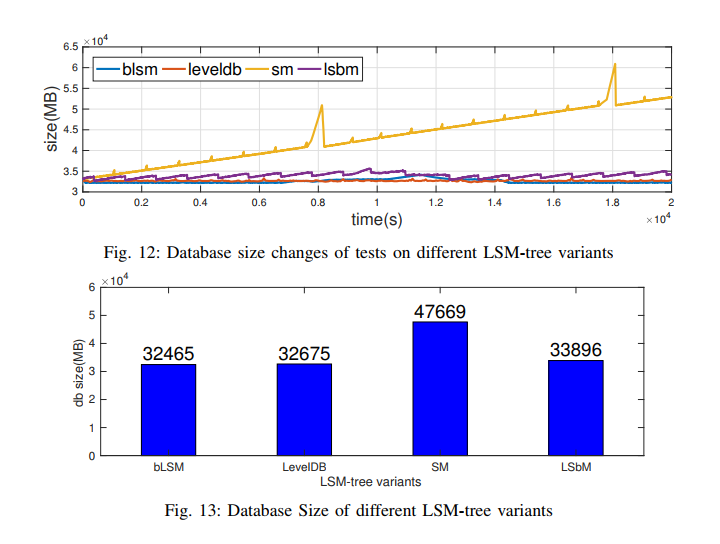
- 测试数据库大小
Related Work
- 为了降低压缩成本,一些生产系统在运行时只对数据进行部分压缩,而在系统空闲时执行完全压缩。在HBase中,前者被称为minor compaction,后者被称为major compaction。然而,在运行时禁用主要的压缩主要会减少对旧数据的压缩。这些旧数据指的是标准LSM-tree中的最后一级数据,与新数据相比,这些数据被访问的频率较低。因此,就像SM一样,这种方法不能避免压缩对缓冲区缓存的干扰。在实际应用中,HBase在密集的写操作中,仍然存在读性能低下的问题
- RocksDB通过编译和利用多种技术来充分利用SSD等基于闪存的存储系统的效率。它将步进合并算法作为通用的压缩方法,并将Key-Value缓存作为特定工作负载的选项
- VT-tree是LSM-tree的一种扩展,用于避免对预排序数据进行不必要的合并
- LSM-trie通过类sm树的合并算法,减小了LSM-tree的写放大,并在各级多排序表结构上优化了随机数据访问性能
- FD-tree与LSM-tree具有相似的思想,并通过分级级联技术进行了增强,以降低内存使用量,如果在第一层找不到对象,则查找需要多次磁盘访问
- LOCS利用flash通道之间的内部并行性来改进基于ssd的lsm树
- cLSM是一种lsm树变体,支持使用多核处理器的可扩展并发性
- wisckey,将key和value的存储分离,显著消除了LSM-tree压缩在SSD上的写放大问题
Conclusions
- LSM-tree 对于写密集型工作负载非常有效。然而,由于读和写密集型工作负载同时存在,压缩导致的缓冲区缓存失效会周期性地降低缓存性能,因为缺少具有高局部性的数据块。现有的解决这个问题的方法,例如通过 KV-store 缓存绕过缓冲区缓存,通过减少压缩频率使用 SM 树,以及其他方法,对于某些工作负载都是有效的。这些方法有两个限制。
- 首先,优化一直专注于某些工作负载模式,代价是损害其他模式的性能。例如,SM-tree 通过延迟压缩减少了压缩导致的缓存失效的数量,但非完全排序的 lsm-tree对于范围查询的效率较低。
- 通过在 DRAM 中构建独立的缓存,KV-store对于频繁的随机数据访问是非常有效的,但对于范围查询是无效的。
- 专用的压缩服务器方法是有效的,因为频繁访问的数据也是 lsm 树中通过其预热过程最近压缩的数据,但这一假设在实践中可能并不总是正确的。
- 其次,KV-store和专用的压缩服务器方法需要额外的内存资源。
- 在本文中,我们提出了 LSM-tree,这是一种低成本的解决方案,通过在磁盘上添加一个小型的压缩缓冲区,它在从根本上解决现有方法的失效问题和其他问题方面发挥了三个主要作用,并保留了 LSM-tree 和其他方法的所有优点。
- 首先,压缩缓冲区是有选择地、自适应地构建和管理的,其中数据块与缓冲区缓存中的数据块保持一致。因此,最小化和消除了 LSM 树诱导的失效。
- 其次,对于随机访问和范围查询,lsbm-tree 最好地利用了缓冲区缓存和磁盘。
- 最后,只有在必要时才构建压缩缓冲区,没有计算开销。
- 在只读或只写的工作负载下,压缩缓冲区会自适应地收缩并最终消失。因此,额外的资源只与很小的磁盘空间有关
- 图 18 根据内存缓存的效率(y轴,命中率)和磁盘中范围查询的效率(x轴,数据访问吞吐量),对五种代表性的基于 lsm 树的方法进行了全面比较。
- LSM-tree 可以很好地执行磁盘中的范围查询,但会导致压缩导致的缓存失效,从而降低缓存性能,
- 而 SM-tree 的性能结果则相反。
- kv-store 和 Dedicated server 方法都保持了完全排序的树结构,因此它们保留了磁盘上的范围查询的高效率。但是,在某些工作负载下,它们的缓存性能较高,而在其他工作负载下,它们的缓存性能不佳,因此在某种程度上,它们的缓存性能总体上有所下降。
- 相比之下,lsbm-tree 在磁盘范围查询效率和内存缓存效率方面的性能最好

- Utterance
