AC-Key
2022-11-22|2023-2-10
DieInADream
type
status
date
slug
summary
tags
category
icon
password
Property
Feb 10, 2023 09:12 AM
- AC-Key: Adaptive Caching for LSM-based Key-Value Stores

Abstract
- LSM 因为用于提升写的分层结构有严重的读放大,缓存是提升读操作性能的主要技术,设计高效的缓存算法很有挑战性,因为分层的结构掩盖了缓存特定键的成本和好处,点查找和范围查询操作之间的权衡进一步复杂化了缓存替换决策。
- 我们提出了 AC-Key,an Adaptive Caching enabled Key-Value Store,AC-Key 管理三种不同的缓存组件,KV Cache,key-pointer Cache,Block Cache,根据负载分别调整对应的大小,AC-Key 利用新的缓存效率因子来捕获缓存条目的缓存成本和优势的异构性。通过修改 RocksDB 实现了 AC-Key,测试表明在各种负载下性能好于 RocksDB,在阶段变化的工作负载中,甚至比最好的离线固定大小的缓存方案更好。
Intro
- 缓存是提高读性能的主要技术之一,因为工作负载通常会显示一定数量的访问局部性,研究表明在 LSM KVs 企业负载的读操作(不仅是点查询还有范围查询)中展现出了 "hot spots"。一些大规模 RocksDB 的生产系统也表现出了很强的局部性,其中少于百分之三的数据会在 24-hour 内的 UDB 负载中再被访问,在 ZippyDB 中的负载大约有 1% 的 KV 对占据了 50% 的总读取。
- 点查询表现出热点
- ATC13 Tao: Facebook’s distributed data store for the social graph
- 13 Storage and performance optimization of long tail key access in a social network
- 12 Workload analysis of a largescale key-value store
- 范围查询表现出热点
- 10 Benchmarking cloud serving systems with ycsb
- EuroSys20 Evendb: optimizing keyvalue storage for spatial locality
- 大规模 RocksDB 的热点:
- FAST20 Characterizing, modeling, and benchmarking rocksdb key-value workloads at facebook
- 设计一个高效的 LSM 中的缓存算法有两个挑战:
- LSM 是一个多层设计,每个缓存的 KV 对节省的 I/O 可能是不同的。越深层的 KV 对被缓存节省的 I/O (缓存收益)就更多,此外,一个键值对所占用的 DRAM 缓存大小(缓存成本)也因键值和键值大小的不同而不同,对缓存方案来说,评估成本和收益并据此做出替换决策是一项挑战。
- 两种读操作,点查询和范围查询,表现出了不同的缓存要求。
- 点查询更喜欢独立的 KV 对的缓存来保证空间效率(RocksDB、Cassandra),如果 value 很大,另一个选择则是缓存 Key-Pointer (Cassandra)。
- 范围查询不能从缓存零星的 Key 来获益,所以人们求助于缓存块来支持范围查询 (LevelDB、RocksDB)
- 很难在 KV、KP、Block 缓存中权衡,因为他们都有各自支持的负载。此外,设计一个自适应的可以处理动态负载的缓存机制就很有挑战性。
- 现有的缓存方案只考虑到了 KV/KP/Block 缓存的一到两种,而且针对某种类型的项都只有固定分配的缓存大小,因此这些方案不能利用他们所有优点来应对各种工作负载场景,也不能在工作负载变化时调整缓存空间。此外,据我们所知,在独特的 LSM-KVS 场景中,目前还没有解决异构缓存成本和收益的工作。
- LevelDB/RocksDB/Cassandra
- Eurosys16 zexpander
- TOS18 A low-cost disk solution enabling lsm-tree to achieve high performance for mixed read/write workloads

- 我们深入研究了 KV/KP/Block 缓存的权衡,提出了 AC-Key,组合了他们的优点来处理不同的负载,AC-Key 对于每种数据项使用了一个指定的缓存组件,每个缓存组件的大小是由提出的 hierarchical adaptive caching 算法来动态调整的,使用了 ghost caches 来指示缓存调整,AC-Key 利用新的 caching efficiency factor 量化不同的缓存成本和好处,以帮助缓存组件之间的边界调整以及每个缓存组件内的替换决策。
Background and Related Work
LSM Background
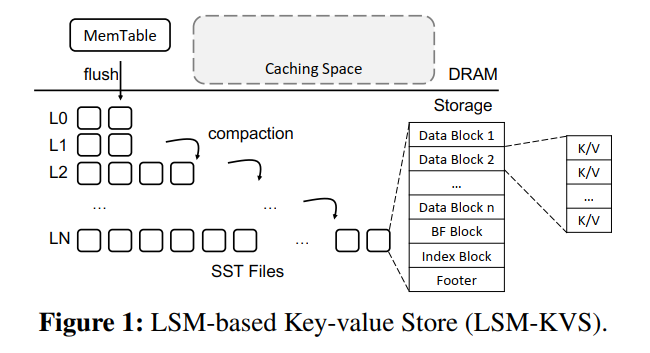
- LSM 由多层组成,每层由多个 SST 组成,每个 Table 由多个 Blocks 组成,Block 是 LSM-KVS 的主要存储 I/O 单位。
- Get 操作流程:先访问 Memtable,然后 L0 每个 SST,然后 L1 到 LN。如果在 Memtable 中找到了 Key,将没有任何存储开销地返回值,否则将去磁盘上检索,首先检查 SST 的布隆过滤器,如果布隆过滤器表明 Key 不存在将跳过 SST,否则会读索引块来定位对应的数据块,最终,检索数据块并搜索 Key。因此,一个 KV 存储需要最多三次存储 I/O (实际上这里算的有问题,布隆过滤器可能误报)
- Range Query:使用了一个起始 Key 和结束 Key 或者具体的要返回多少个 Value 来执行,为了执行范围查询,KVS 使用了一个 Seek 函数来构建合并迭代器,该迭代器可以同时遍历 Memtable、SST,KVS 将调用 Next() 函数返回下一个大点的 Key,当 next 返回的 Key 大于结束 Key 或者返回的 KV 数量达到了给定的数量,范围查询将被终止。
Related Work
Caching Schemes in LSM-KVS
- 三种缓存形式如下图所示
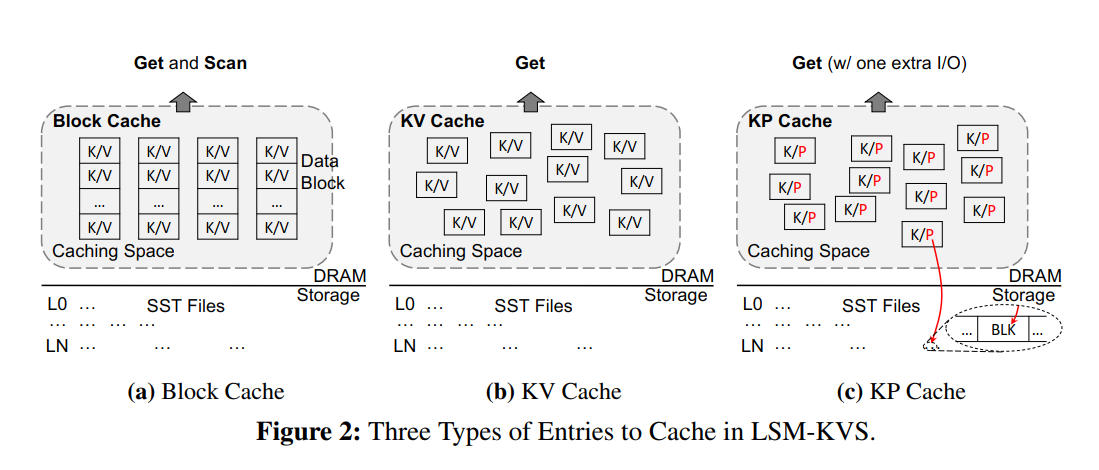
- LevelDB 只使用了 BlockCache,对应的 Block 可以是数据块,也可以是索引块,也可以是布隆过滤器块,BlockCache 使用了 <SstID | BlockOffset> 来索引,对于点查询和范围查询都可以获益,只要目标 Block 被缓存就可以节省存储 I/O,然后 BlockCache 服务点查询并不空间高效,因为必须缓存整个 Block 即便只有很少的 Key 被频繁访问。
- RocksDB 既有 BlockCache 又有 KVCache,KVCache 可以存储用于服务点查询的 KV 对,然而,BlockCache 和 KVCache 的大小是预定义的且固定的,当 KVCache 开启了,点查询首先找写缓冲区,没找到就直接检索 KVCache,如果也没找到,将遵循原有的读取 BlockCache的方式,然后将 KV 插入到 KVCache 中,范围查询使用了 BlockCache 来支持。
- Cassandra 没有 BlockCache 但是有 KVCache 和 KPCache,当命中 KPCache 的时候,点查询可以使用一个存储 I/O 来读取到数据,跳过存储组件中所有较浅的级别。相比于 KVCache,KPCache 对于大 Value 的空间效率更高,但是需要一次额外的 I/O。KPCache 和 KVCache 一样不能处理 Range Query,当从 KPCache 提升一个 Key 到 KVCache 的时候,Cassandra 不会移除 KP 项。
- Cassandra 缓存示意图
- 其中 RowCache 对应了本文的 KV Cache
- Key Cache 对应了 KP Cache

- zexpander 是一个只缓存 KV 项的 KVS,该方案将缓存空间分区成一个压缩的空间 Z-Zone 和一个未压缩的空间 N-Zone,并可以调整两个区域的边界
- LSbM 有一个很小的磁盘上的 compaction buffer 来保存 compaction 过程中删除的老的但是热的数据,来减少 block cache 因 compaction 的失效,但是需要额外的存储空间,而且没有利用更高效的 KV/KP Cache 支持点查询的优势。

General Caching Algorithms
ARC
- FAST03
- 页缓存替换算法研究了几十年 [1966 A study of replacement algorithms for a virtual-storage computer],ARC 算法是一个动态的页替换算法,用于 DRAM 中的页缓存的管理。
- 如下图所示,ARC 把缓存空间分为两部分,recency cache 和 frequency cache,每个都是 LRU cache,一个页当第一次被访问时加入到 recency cache,如果该页在淘汰之前第二次被访问,将被认为是一个频繁访问的页,然后移动到 frequency cache。
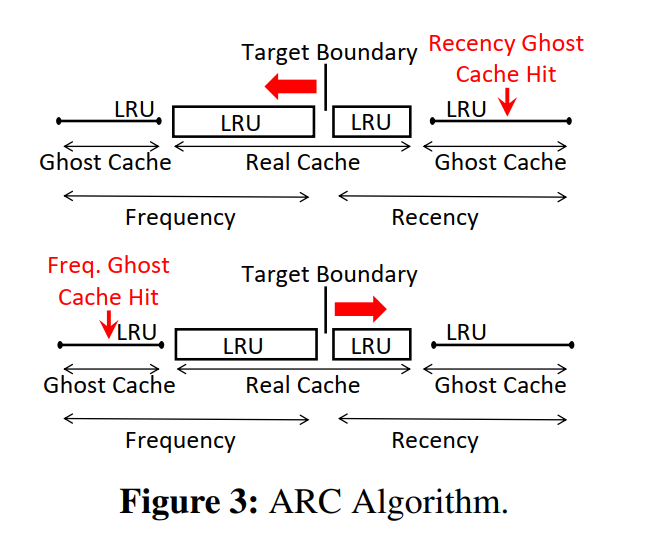
- 在 recency cache 和 frequency cache 的空间分布是动态的,ARC 使用了两个 ghost caches 来存储两个缓存队列淘汰页的元数据(页号),存储在 ghost 中的页只会成为一个未来的引用,用来调整空间分配。相比于真实 cache(例如,缓存存储实际的页内容),ghost 的缓存大小开销是可以忽略的,因为只存储了页号。
- 当命中了 recency ghost cache,意味着 recency cache 需要更大,所以目标边界需要左移,反之亦然,最终,相应的真实缓存的大小将根据负载增加或减小。
CAR
- FAST04
- CAR 也维护了一个动态分区,和 ARC 不同的是使用了 CLOCK 来代替 LRU 管理每个缓存组件来减小开销。
H-ARC
- MSST14
- 使用了非易失内存来同时缓存 Clean and Dirty 数据,并提出了一个分层算法来自适应地处理页替换。
Summary
- 这些基于页的缓存算法不适用于 LSM-KVS,因为他们都是基于相同的页大小和缓存收益,而在 LSM 中缓存项大小和缓存收益不是均与分布的,相似的,纯粹的基于频率的缓存淘汰算法,如 SoCC02 的 WLFU,以及替换策略,如 ToS17 的 TinyLFU 都是假设了条目大小和缓存收益相同,并根据访问频率做出替换决定。但是 LSM-KVS 中数据项的大小和缓存收益需要和访问频率一起考虑,Web 缓存算法经常把项大小信息考虑进去了,LSM-KVS 除了考虑项大小以外还要考虑不同项大小带来的不同的缓存收益。例如,缓存一个深层次的 KV 相比于缓存一个低层次的将节省更多的 I/O,这种 LSM-tree 层次结构的特殊知识应该用来帮助 LSM-KVS 中的缓存决策。
Motivation
Unique Challenges in Caching for LSM
- 相比于页缓存替换算法,页面有相同的大小,而 LSM 的 KV 不一定大小相等,所以 LSM 的缓存算法需要考虑大小差异来设计替换算法。
- 基于 HASH 的 KVS 不支持范围查询,相反,LSM 有两个不同的读操作,点查询和范围查询,展现出了完全不同的缓存要求,给 LSM 缓存算法的设计带来了额外的挑战。
- NSDI10 Cheap and large cams for high performance data-intensive networked systems
- SOSP11 Silt: A memory-efficient, highperformance key-value store.
- 基于 B+tree 的 KVS 同时支持点查询和范围查询,LSM 不同的是有一个多层的结构来区分了不同层次的缓存收益。越深层次 KV 驻留,更多的存储 I/O 可以因为缓存节省,除此以外,原生的如 compaction/flush 的操作在 B+Tree 对应的 KVS 中是不存在的,但是他们将让缓存项失效,所以在设计中需要特殊对待。
- Mysql
- 为了驱动我们的设计,我们讨论了两个 LSM 缓存的问题:
- 缓存哪些数据
- 如何执行替换
What to Cache in LSM-KVS
Lesson 1: The merits of caching KV and KP entries should be combined to efficiently serve point lookups
- 缓存 KV 和 KP 条目的优点应该结合起来,以有效地服务于点查找
- 点查询很自然地想到缓存 KV 项,但是当 value size 很大的时候,或者访问不是那么频繁的时候,另一个可选的方案则是缓存 KP,使用 KP 则可以在缓存中装更多的数据项,这样的 KP 的命中率将更高,相比于 KV Cache,可以节省更多 I/O,而 KV 项命中可以节省更多的存储 I/O 因为 KP 命中了还需要一次磁盘访问,另一方面缓存 KP 在 value 更大的情况下是空间上更高效的。
Lesson 2: Cached blocks and KV/KP entries each have their advantage to support range query and point lookup
- 缓存块和 KV/KP 条目都有各自的优势来支持范围查询和点查询
- KV/KP 都不能用于范围查询,给定范围查询的起始键,不能通过只检查零星缓存的 KV 或 KP 条目来确定下一个更大的键,因此如 LevelDB/RocksDB 中使用了 BlockCache。
- BlockCache 可以用于服务点查询,然而保留一整个块对于点查询来说不够空间高效,因为它在 DRAM 中保存了一个完整的块,即使只有几个键经常被查找。除数据块外,经常访问的索引块和 bloom filter 块( BF 块)也被缓存在 Block Cache 中
How to Perform Replacement
- 缓存各种数据项各有各的支持的负载。然而,为包含所有这三种不同条目的缓存设计替换算法是具有挑战性的。

- 一个很直接的方法就是把所有的缓存项一视同仁,并使用现有的缓存替换算法 LRU/LFU 来管理缓存,每个数据项根据相应的淘汰策略被插入或者被淘汰。因此,缓存的KV 条目、KP 条目和 block 中缓存条目的数量完全由访问模式决定,然而,这种“统一”的缓存方法过于简化,无法区分这些缓存条目之间的区别。
- 不同的缓存项有不同的大小,例如 BlockCache 单个的大小可以占据大约数十个甚至上百个 KV/KP 的大小
- 不同缓存项可以节省的 I/O 数量不同,例如 一个缓存块如果命中节省一个 I/O,但一个缓存的 KV 条目可以为所有 sst 被访问的点查找节省多个存储 I/O。此外,KV/KP 条目在不同的级别将有不同的存储 I/O 的节省。一般成本敏感的缓存方案没有对 LSM 的缓存开销和收益做分析。
- 如果有单次大范围查询,获取的块将从缓存中逐出有用的条目,而不会带来任何好处
Lesson3: 缓存算法应该考虑不同缓存条目之间DRAM大小和存储I/O数量的差异,尊重LSM-KVS的独特层次结构
- 另一个方法则是考虑固定大小的 KVCache/KPCache/BlockCache, 基于独立的淘汰算法 LRU/LFU。这样的话,缓存对大型单遍范围查询具有弹性(如前所述),因为每个缓存组件的容量是有限的,不会影响其他缓存组件,然而,这种固定大小的方法存在一些问题。
- 一开始很难直接得到正确的规模分布
- 即使我们可以在一开始就有一个合适的固定大小的配置,但是随着时间的推移,工作负载的访问模式可能会发生变化,因此在以后也可能不合适。例如负载有阶段性变化,从 range query 主导到 point query 主导,如果固定的配置适合于最初的范围查询,即大部分缓存空间用作块缓存,那么在点查找阶段,它显然是没有效率的。
Lesson 4: 缓存算法应该能够适应工作负载的变化
AC-Key Design
- AC-Key 缓存三种数据,KV/KP/Block,各自一个缓存组件。区别于固定大小的缓存组件,AC-Key 为每个组件使用了动态大小,通过使用提出的 分层自适应缓存算法 来调整大小,考虑到不同缓存项多样化的开销和收益以及独一无二的分层结构,使用提出的 caching efficiency factor 定量地指导缓存组件之间的大小调整以及每个缓存组件内的替换策略。
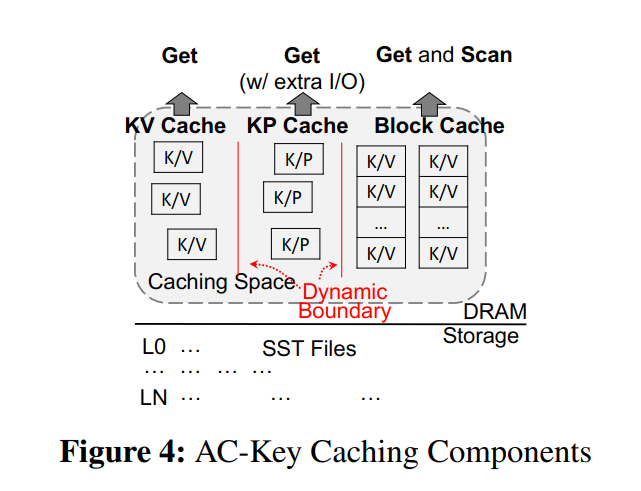
AC-Key Caching Components
- KV/KP/Block Cache 使用了 E-LRU 来管理,E-LRU 是一个使用了基于淘汰的缓存效率因子的优化后的 LRU。
- KVCache 直接存储 KV 对,KP Cache 存储 KP,指针的格式为 <SstID|BlockOffset>,当一个 KPCache 命中,花费一个 I/O 来抓取对应的包含该目标 KV 对的 DataBlock。BlockCache 存储了频繁访问的 blocks,既可能是数据块,也可能是索引块,甚至过滤器块。
- Remarks on the KV and KP Cache:点查询中,如果查询的 Key 第一次被访问,首先会被读取到 KPCache,缓存在 KPCache 中的 Key 称之为 warm-key,如果 warm-key 再次命中,将认为该 Key 为 hot key,我们预计它在将来有更高的可能性被再次访问。因此将该 Key 提升到 KVCache 来潜在地为未来的访问节省更多的 I/O。不同于 Cassandra 仍然把 KP 保留在 KPCache 中,AC-Key 会把 Key 从 KPCache 中移出来避免数据冗余并实现更好的空间效率。
- 数据提升 KPCache -> KVCache (并移除 KPCache)
- 现有的设计中,我们不会让热数据从 KVCache 降级到 KPCache,因为我们不再拥有对应的指针信息,另一个可选的方案是同时存储指针和 value 信息在 KVCache 中,然而会占据额外的 KVCache 缓存空间,所以我们没有使用这种方法。作为一个优化,如果 value 大小小于指针大小,我们的场景下是小于 24B,我们将把 value 和 Key 一起放在 KPCache 而不再使用指针来节省 I/O,不然会导致更多的 DRAM 空间消耗。这个条目还需要一次额外的命中来提升到 KV 缓存。AC-Key 不直接插入数据项到 KVCache,原因是如果整个 Key 不够热,比如之后不太可能再被访问,会把其他本来热的数据给淘汰出去,例如,一个工作负载在特定的时间开始访问大量的小值键,没有第二次命中,这些键将占用整个 KV 缓存,踢出有用的 KV 对,而没有带来任何好处。
Get Handling
Get Existing Key
- 假设 K 是要访问的键,首先,查询 Memtable,如果没找到,再找 KVCache 和 KPCache:
- case1: KVCache 命中,那么该值直接返回,无 I/O 产生。
- case2: KVCache 丢失但是 KPCache 命中,使用缓存的指针 <SstID|BlockOffset> 作为 block handle,AC-Key 将检查是否数据块已经被缓存在 BlockCache 中,如果没有,将首先把数据从磁盘上加载到 BlockCache,使用二分搜索定位对应的 KV 对,然后处理读请求,除此以外,Key 将被迁移到 KVCache,把缓存项从 KP 格式转换成 KV 格式
- case3:KVCache/KPCache 都不命中,AC-Key 将逐级检查每个已排序的 run,识别每个键范围与 K 重叠的SST,从最小到最老。一旦找到了包含该 Key 的 SST,将停止搜索并直接返回结果,除此以外,KV 对的地址信息例如指针,将被记录缓存在 KPCache 中。
- 在上述的 case3 中,检查一个 SST 时,首先访问该 SST 的布隆过滤器,如果布隆过滤器不在 BlockCache 中,那么将从磁盘上读取上来并插入到 BlockCache 中,如果布隆过滤器指示该 Key 不存在于 SST,AC-Key 将跳过 SST 并处理下一个 SST,否则,AC-Key 将访问对应的索引块来缩小查询的范围,并确定要搜索的数据块,索引块和数据块都会被提升到 BlockCache 中,如果缓存中本来没有的话,BlockCache 存储的数据还是和以往的 BlockCache 是一致的。
Get Missing Key
- 当查询一个不存在的 Key,KV/KP Cache 都会不命中,Block Cache 将被搜索到相应的BF Block,如果命中一个存储 I/O 将被节省。读取不存在的 Key 时最糟糕的情况因为所有具有重叠键范围的 SST 都会被检索,然后使用了缓存的 BF Blocks 的话可以节省很多 I/O 开销。
Flush Handling
- Flush 操作持久化 Memtable 到磁盘,可能新插入到 Memtable 的数据将淘汰相应的缓存项,只要数据的新版本在 Memtable 中,缓存中的老数据项都不会产生影响,因为点查询操作首先查询 Memtable,但是 KVCache 和 KPCache 中的缓存项必须在 Key 被刷新到存储之前被同步,从而避免返回老的数据。
- 有两个同步时机的选择:在 Put 期间或者在 Flush 期间
- 如果是在 Put 期间,将检查每一个 Put 中的 KV 和 KP 缓存中潜在的过时条目,并相应地更新 KV 条目或删除 KP 条目。注意在 PUT 期间,AC-Key 不能更新 KP 项因为最新的值还没有写到 SST 中,所以不知道指针指向的位置,该方法引入了显著的性能开销,因为每一次 PUT 操作需要额外的检查,除此以外,如果一个 Key 在刷回 Memtable 之前得到了多次更新,将不得不重复检查 KV/KP Cache,显著增加了同步开销。
- 因此 AC-Key 采用了另一种方式来同步缓存,即在 flush 时,这样做可以汇集大量的更新操作并且只会为每个 Key 同步 KV/KP Cache 一次。除此以外,在 flush 时,AC-Key 可以计算出 keys 在 KP Cache 的新指针并相应更新。
Compaction Handling
- Compaction 也会影响 KP/Block Cache,因为创建了新的 SSTs 并删除了老的 SST,老的 SST 删除可能包含已经缓存了的 Blocks,这些被删除的 SSTs 也可能包含被缓存在 KP Cache 中的指针引用的数据块。但是不会影响 KVCache,因为 compaction 重排序了并整合了老的 KV 对,而没有插入新的 KV,当 compaction 影响了任何缓存的 KP 项或者 blocks 的时候,AC-Key 更新 KP/Block Cache。(开销???)
- 对于 KP Cache,compaction 影响的 KP 项会被 AC-Key 识别并更新指针来指向新的包含该 Key 的数据块。对于 Block Cache,如果一个缓存的数据块在 compaction 时变得无效了,AC-Key 将使用 compaction 生成的新的数据块来代替无效的数据块,从而避免无效的 Block 浪费 BlockCache 的容量。新生成的数据块的键范围可能和老的不完全一样,AC-Key 将选择和老的缓存块有最大重叠范围的块,然后将其重新填回 BlockCache。相似的,失效的缓存 BF 块和索引块也被新的有最大重叠范围的给替换。这样的替换策略不会导致任何额外的 I/O,因为新的块在 compaction 过程中内存中会生成。
- 这里有疑问,如何找到老的缓存块?直接通过老的 SST 的 ID 一个个去找?
Caching Efficiency Factor
- 为了定量分析缓存项的成本和收益之间的权衡,我们提出了考虑到LSM-KVS的独特级别结构的新的缓存效率因子。使用这个缓存效率因子,ACKey 将 LRU 改进为 E-LRU,以管理每个缓存组件中的缓存收回,并将 ARC 修改为 E-ARC,以调整每个缓存组件的大小。本节将介绍缓存效率因子和 E-LRU,下一节将讨论 E-ARC。
- 为每个缓存项定义了 Caching Efficiency Factor E (E 代表效率),含义时每字节 DRAM 缓存空间节省的 I/O 数 ,其中 E 代表一个缓存项的缓存效率,b 代表如果缓存的话节省的 I/O 数,s 代表由这个项占据的缓存空间。
- 例如,一个通用的 KV 项将占据几个甚至上百个字节,一个 KP 项将通常占用少于 100B,一个缓存块一般占用 4~16KB,b 表示缓存该条目时节省的 I/O 数量。

- 函数 f(m) 取决于 LSM-KVS 的实现,通常 ,我们必须从搜索路径上的一个 SST 读取 m 个 bloom 过滤器,以及包含查找键的 SST 中的一个索引块和一个数据块。需要搜索的 SST 的数量 m 是由 Key 所在的层次 l 估计的
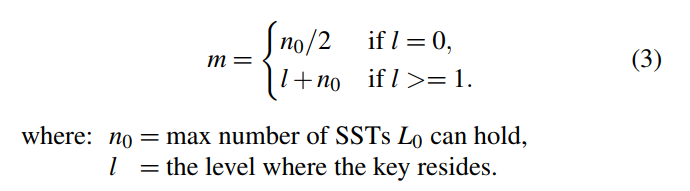
E-LRU
- 传统的 LRU 只考虑数据访问模式,而不用考虑不同缓存项的开销和收益,所以我们提出了 E-LRU,基于效率的 LRU,E-LRU 检查最少使用的缓存条目,并逐出缓存效率最低的条目。a 的值取决于缓存条目的缓存效率因子 E 的变化。,v 代表缓存组件中抽样条目的缓存效率因子 E 的标准偏差。v = 0,意味着缓存的数据项有一致的效率,a = 1,E-LRU 退化为最初的 LRU 算法,从列表中删除最后一个条目。v 越大,效率 E 的方差越大,更大的 a 应该用来选择一个更好的候选人驱逐。当前实现中,我们对 a 有一个限制来避免进行淘汰决策时 AC-Key 检查太多数据项。为了简单起见,我们使用 E-LRU,但是其他成本敏感的缓存方案可以在这里使用我们建议的缓存效率因子进行调整。
HAC: Hierarchical Adaptive Caching
- 分级自适应缓存(HAC)有一个两级的层次结构来管理不同的缓存组件。在上一层,缓存被分为两个部分:点缓存和块缓存。
- 点缓存和块缓存之间的边界是动态调整的。
- 在较低的层次上,点缓存进一步分为 KV 缓存和 KP 缓存,边界也可调。
- HAC 维护 ghost 缓存来保存从 KV, KP 和 Block Cache 中被驱逐的条目的记录。
- 在上一层,有两个 ghost 分别缓存点缓存和块缓存
- 而在较低的一层,有两个 ghost 缓存 KV 和 KP 缓存。
- 原始的缓存被称为真缓存,这里 KV 和 KP 真实缓存共同组成点真实缓存。ghost 缓存不保存真正的条目,而只保存被逐出条目的元数据。
- ghost cache 的命中意味着如果对应的实际缓存更大,则可能是真正的缓存命中。利用带有缓存效率因子的虚缓存,设计了 E-ARC (caching efficiency enabled ARC) 来调整相应的真实缓存的大小。
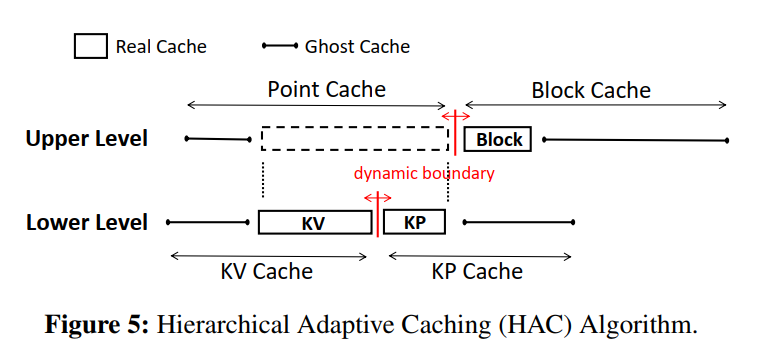
Lower-Level HAC
- AC-Key 使用了 E-ARC 来管理低 Level 的 HAC,在低 Level 的 HAC,点查询缓存被分成了 KV 真实缓存和 KP 真实缓存(用 R 表示),点查询缓存对应的 KV Cache ghost cache 大小则为总大小减去实际的 KVCache size,KPCache 同理。如下等式所示:
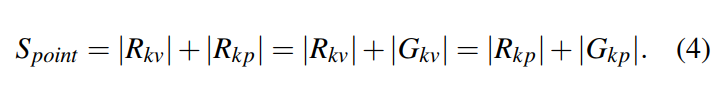
- 我们将展示 E-ARC 如何在以下情况下处理缓存命中和未命中:
- Case1:Real Cache Hit:缓存在 KVCache 或者 KPCache 的真实缓存中命中,把命中的条目移到 的 MRU(Most Recently Update)端,特别地,如果是在 命中,AC-Key 需要一次额外的 I/O 来获得值,然后 KV 被插入到 。
- Case2:KV Ghost Cache Hit:在上命中意味着 的大小需要变的更大,通过 向 KPCache 的一边移动目标边界 ,其中 E 就是 的缓存效率因子,k 是一个可控制的学习率,再从存储上提升以后,插入预取的 KV 到 的 MRU 端。为了给 KV 项腾出位置,如果目标边界在 以内,从 中淘汰数据,意味着 的目标大小小于自身实际的大小。
- Case3:KP Ghost Cache Hit:与 Case2 类似
- Case4:Cache Miss:从存储中检索数据项并缓存在 KPCache 中,为了为 KP 项腾出位置,如果目标边界在 KVCache 内,从 KVCache 中淘汰,否则从 KPCache 中淘汰
- KPCache 和 KVCache 的真实缓存的目标边界暗示了实际边界应该移动的方向,实际边界通常会滞后于目标边界。高阶操作顺序如下:
- ghost 命中调整目标边界;
- 条目的插入或提升使实际边界向目标边界偏移,从而更新实际缓存大小;
- 根据新的真实缓存大小使用上面等式调整 ghost 缓存大小;
- 真实和 ghost 缓存执行驱逐,如果有必要使用 E-LRU 适应更新的大小
- Remarks on E-ARC: 虽然我们遵循规范 ARC 算法的类似逻辑,但原始的 ARC 没有大小和代价的差异。对于原始的 ARC,每个项节省的块访问 b 和空间开销 s 总是相同的。E-ARC 的定义 是原始 ARC 的一般化,而 ARC 对调整的定义是 E-ARC 公式的特例,即 E=1。
Upper-Level HAC
- 在 HAC 上层重新应用了 E-ARC 来调整 PointCache 和 BlockCache 的边界,PointCache 和 BlockCache 都有自己的真实缓存和 ghost 缓存,从 PointCache 淘汰的数据项将插入到 ghost,淘汰的数据项也会相应地插入到 KV/KP Ghost Caches,和低级别的 HAC 是类似的:
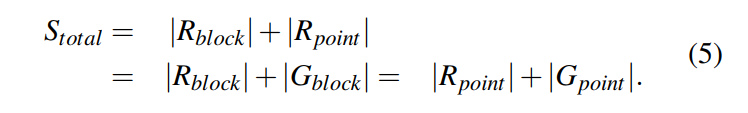
- Target Boundary Adjustment:Block ghost 命中将移动 PointCache 的真实缓存边界,也是 。其中 E 为被命中 Gblock 上的条目的缓存效率因子,k 为前面定义的学习率。所以,PointCache 的目标大小将按照 D 来减小,然后,在较低的层次中,调整量将在 Rkv 和 Rkp 的目标尺寸之间按当前目标尺寸比例分配。
- 如果 PointCache 的 ghost 命中,原理是一样的。但是 Gpoint 的缓存效率因子 E 通常大于 Gblock,因为一个 PointCache 项花更少的内存空间但节省更多的 I/O。相应地下层的 ghost 也会命中,下层的目标边界会首先调整,然后调整上层。
- Actual Boundary Adjustment:block miss 时需要插入这个块到 BlockCache,如果当前 BlockCache 大小加上新块的大小大于目标的块大小,块缓存就不再扩张,将从它自己中淘汰一个块来新进来的块腾出空间。否则,当前 BlockCache 大小加新块大小小于目标 BlockCache 大小时,BlockCache 将插入新块扩张自己,PointCache 将缩减来为 BlockCache 的扩张腾出空间。超过一个KV/KP项将被淘汰,因为一个块通常比 KV/KP 大,KV/KP 淘汰的数量将基于现有的 KV/KP 实际缓存大小的目标大小。
- 另一方面,当缓存要求更多容量,(也就是说,当新的入口插入 KP 缓存,或者当 KP 条目被提升为 KV 缓存和需要更多的空间),HAC 估计增长后的新的点缓存大小和比较它与目标点缓存。如果估计的新点高速缓存大小在目标点高速缓存内,那么块高速缓存的一个区块将被移除,为点高速缓存的增长留出空间。另一方面,如果估计的新点缓存大小高于目标点缓存大小,点缓存将不会扩展,并且驱逐将在点缓存内发生,在当前目标 KV 和 KP 真实缓存大小之后。一个问题是,增加少量的点缓存的大小可能导致整个块从块缓存逐出。为了解决这个问题,直到目标边界在 Block Cache 中至少有一个块大小(通常是 4KB 或 16KB), HAC 才会从 Block Cache 中驱逐块。换句话说,只有当目标点缓存的大小比当前实际的点缓存的大小大整个块的大小时,点缓存的大小才会以从块缓存中移除为代价增长。
Reduce Ghost Cache Size
- 在ARC设计中,当一个页面从实际缓存中被逐出时,页面内容将被删除,只有页码保留在虚拟缓存中。与页面内容相比,页码的大小可以忽略不计。类似地,在 ACKey 中,Block cache Gblock 只存储块句柄的格式为 <SstID|BlockOffset>; (在我们的实现中是 24B) 与缓存块内容(通常是 4~16 KB)相比,这也是微不足道的。但是 PointCache 中的 Ghost cache 开销是不能忽视的,例如,假设一个 key 尺寸 16B 和值大小 100B,一个真正的 KV 条目需要 116B。当被逐出真正的缓存,这个条目的值被丢弃,key 插入 ghost cache 仍以 16B 为 Key 。与值大小和指针大小相比,键的大小不再是可以忽略的,ghost 缓存可能会占用有限的缓存空间的很大一部分,降低缓存效率。
- 我们提出了两种方法来减少虚缓存的空间开销。
- 首先,AC-Key 不使用被逐出的 KV 或 KP 条目的原始密钥,而是将被逐出的密钥的哈希值存储为指纹。这样,AC-Key 减少了虚缓存大小的开销,同时牺牲了虚缓存命中精度。哈希碰撞将导致假阳性 ghost hits,导致不精确的调整决定。在我们的实现中,我们发现哈希值为 4B 显示了 ghost 缓存开销和准确性之间的良好平衡。
- 虽然使用基于哈希值的指纹来替换 ghost 缓存中的密钥减少了开销,但一个哈希值(例如,4B) 与真正的 KV 和 KP 缓存相比仍然占用了大量的空间。我们进一步提出了另一种优化方法,当自适应方案在 KV、KP 和 Block cache 中实现良好的容量分配时,通过禁用 ghost 缓存来消除这种 ghost 缓存开销。如果所有缓存组件的命中率变化保持在阈值 q (称为 ghost 缓存关闭阈值,默认为 5%)内,ghost 缓存机制将被关闭,ghost 缓存所占用的空间将被真正的缓存回收。当 ghost 缓存空间被释放时,真实缓存的大小将按比例放大,以使用所有可用的缓存容量。之后,当访问模式切换和当前大小分布不利时,命中率的变化将标志着相变。当命中率波动超过阈值 q 时,AC-Key 将打开 ghost 缓存机制,直到命中率再次收敛(在阈值 q 内波动)
Evaluation
- 测试环境
- Dell PowerEdge R430 1U Server
- two six-core Intel Xeon E5-2620 v3 @ 2.40 GHz processors
- 64 GB of DDR3 memory
- Ubuntu LTS 18.04 with Linux kernel version 4.15.0
- 372 GB Intel DC P3700 PCIe SSD formatted as xfs
- 负载:
- 100GB database with randomly generated keys
- default key size is 16 B and value size is 100 B
- range scans length 100
- point lookup to range query ratio is set to 1:1
- default skewness as the hottest 1% keys taking up the 99% of the accesses
- learning rate k is 100K
- default ghost cache turnoff threshold θ is 5%
- Data compression Dsiabled
- 基于 RocksDB 6.2 实现的 AC-Key。
- ac-key
- pure-kv: The whole caching space is used as KV Cache
- pure-kp: The whole caching space is used as KP Cache
- rocksdb: Off-the-shelf RocksDB with default setting. Note that RocksDB disables KV cache by default and the whole caching space is used as Block Cache.
- offline: We try combinations of different component size with the granularity of 1/10 of the cache size and select the best fix-sized configuration. Note that such best configuration is determined offline, and is not applicable in a real-time caching system (尝试以缓存大小的1/10为粒度组合不同的组件大小,并选择最佳的固定大小配置。请注意,这样的最佳配置是离线确定的,不适用于实时缓存系统)
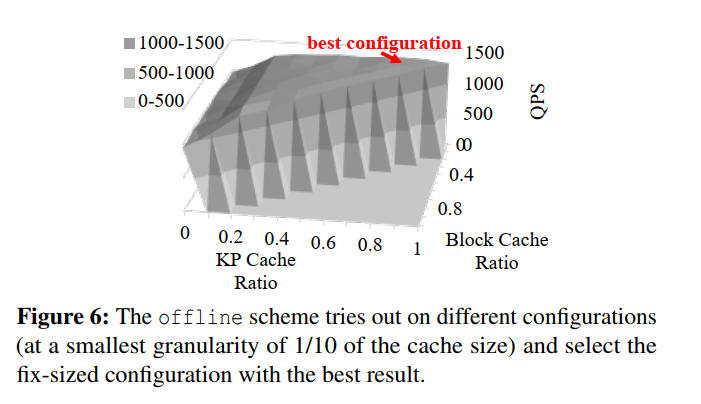
Micro-benchmark
- AC-key, rocksdb, offline 三种方案会随着 cache 大小的增大而 QPS 增加,因为更大的缓存空间可以缓存更多的内容,也就有了更少的缓存 miss,相反 pure-kv 和 pure-kp 因为不支持范围查询所以没有增加,出现了缓存不命中导致 IO。
- Ac-key优于其他只有单一类型缓存组件的缓存方案(优于rocksdb 5.0%~9.1%,优于 pure-kv 47.1%~97.7%,优于pure-kp 52.8%~104.5%)。因为它们不能同时有效地处理点查询和范围查询
- 与 offline 相比,ac-key的性能接近甚至优于 offline,因为它能够自适应地配置每个缓存组件的大小。在某些情况下,ac-key性能更好的原因是,offline 无法用尽所有配置的可能性,因为 offline 仅以总缓存大小的十分之一的粒度来尝试缓存大小
- 不同的偏态: 我们使用RocksDB的原生基准测试工具来改变点查询和范围查询的访问偏度。在图8中,x轴显示了最热1%的访问率范围从1%(无倾斜,均匀分布)到99.9%(非常倾斜)。注意,y 轴设置为对数刻度,以增强可读性。我们可以看到,当访问是均匀分布在所有键上(最左边的条集群)时,所有缓存方案的 QPS 同样低。这是因为在均匀分布的工作负载中,每个缓存方案几乎都没有任何影响。而随着接入偏度的增大,各方案性能均有所提高,ac-key 优于rocksdb 3.6%~57.1%, pure-kv 5%~17.6, pure-kp 7%~16.5。
- Varying range query ratio:我们在工作负载中改变点查询和范围查询的比例,将范围查询的比例从0%(纯点查询)调整到100%(纯范围查询),以创建图9。在该图中,我们看到随着范围查询比率的增加,QPS下降。这是因为范围查询有更多的潜在存储I/ o,占用更多的缓存空间。Ac-key比rocksdb(提高了1.1% ~ 42.6%)、pure-kv(提高了30.4% ~ 54.7%)、pure-kp(提高了43.0%~52.8%)效果好。
- 当范围查询比例从0%增加到20%时,rocksdb的性能有所改善,超过了纯kv。这是因为KV缓存不能提供范围查询。相反,Block Cache支持点查询和范围查询。然而,块缓存的空间效率很低,从而错过了缓存更多有用条目的机会。ac-key自适应结合了Block Cache、KV Cache和KP Cache,具有最佳的性能。
- Varying value size:我们尝试不同的值大小,从50B到200B(图10)。随着值大小的增加,所有缓存方案的性能都会下降。这是因为值越大,读取每个键的存储I/O开销就越大。在数值较小时,Pure-kv的表现优于pure-kp,但随着数值大小的增加,pure-kp的表现会超过Pure-kv。这是因为pure-kv可以缓存的键总数随着值大小的增加而减少,因此pure-kv的性能不如pure-kp。rocksdb的性能仍然比 pure-kv 和 pure-kp 好,因为有一半的请求是范围查询,而KV或KP缓存无法提供这些请求。Ac-key的性能接近于离线,并不断优于rocksdb(5.9%~22.4%)、pure-kv(41.4% ~ 83.6%)和pure-kp(44.5% ~ 96.0%),这是因为Ac-key在调整每个组件大小时使用了分级自适应缓存。
- CPU Utilization Comparison:对于默认设置(5.1),我们通过Linux本机 time 命令记录CPU利用率,并将其绘制在图11中。QPS也被绘制出来以更好地说明这种权衡。我们可以看到,与其他方案(ac-key、pure-kv、pure-kp 和 offline)相比,rocksdb 消耗的 CPU 资源更少,因为它们都使用 Point Cache,因此需要计算插入的每个键的哈希值,以检查它们是否被缓存。我们还可以观察到,尽管 ac-key 有额外的操作来适应缓存组件的大小,但与 pure-kv、pure-kp 和 offline 相比,CPU 利用率并没有显著增加。ac-key 的性能接近离线,优于rocksdb、pure-kv和pure-kp。
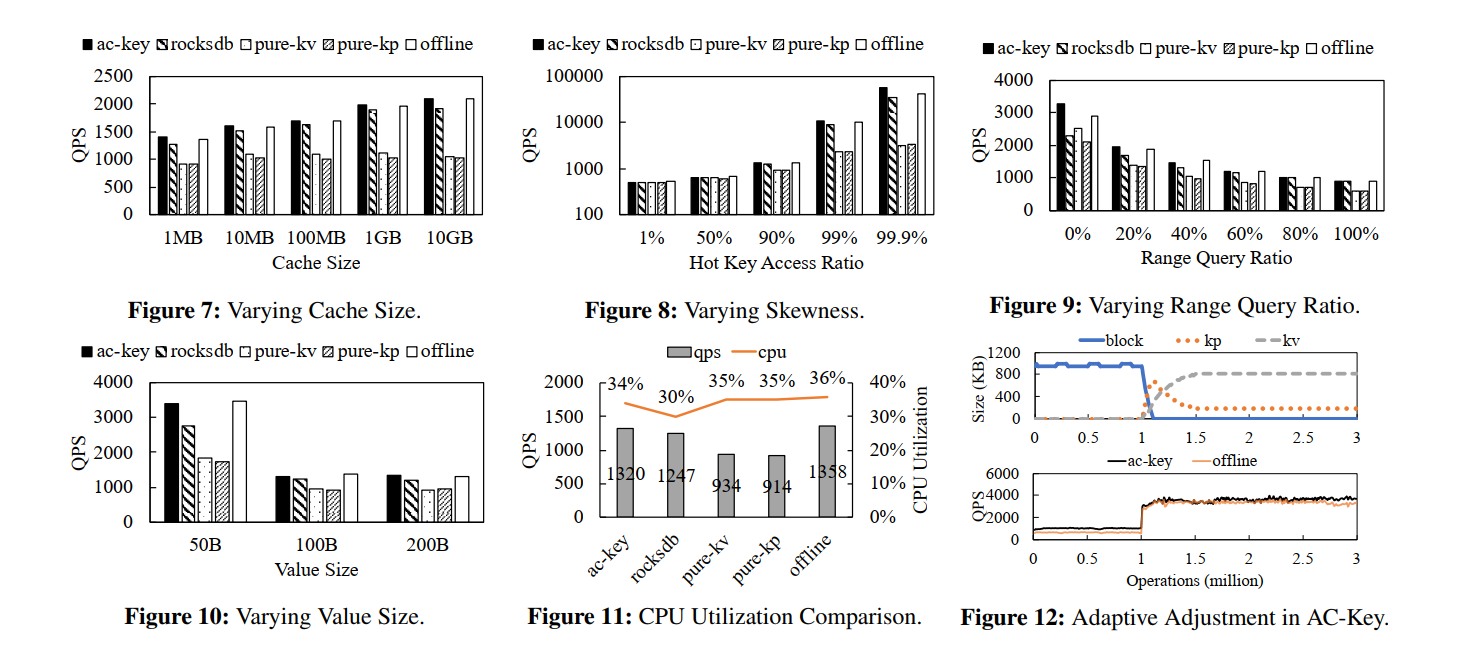
Adaptive Adjustment in AC-Key
- 为了验证 AC-Key 的自适应调整过程,我们构造了一个工作负载,该工作负载分为两个阶段: 1 million range query with random start key, 2 million random point lookup。我们绘制了缓存组件 Block、KV 和 KP 缓存的大小,以显示适应过程的直接证据(图12顶部图)。此外,我们还比较了 ac-key 的实时 QPS 和离线 QPS (图12下图)。
- 从图 12 的顶部图可以看出,在前100万个查询中,KV 和 KP Cache 的大小减小到0,以最大化 Block Cache,因为它们不能提供范围查询。当工作负载在第一个 100 万个查询之后从纯范围查询转变为纯点查询时,块缓存急剧收缩,而 KV 和 KP 缓存开始增长。这是因为点缓存( KV 和 KP Cache)在缓存点查找中空间效率更高,所以 HAC 算法调整有利于点缓存(包括 KV 和 KP Cache)。在开始的时候,KP Cache 比 KV Cache 增长得快,因为每个条目首先缓存在 KP Cache中,只有少量具有第二次访问的热 KV会迁移到 KV Cache 中。在第二阶段的开始,KV 和 KP 缓存都随着它们从块缓存中窃取空间而增长。当 Block Cache 的大小下降到几乎为零时,KV 和 KP Cache 开始争夺空间,此时 KP Cache 开始缩小。KP 和 KV 缓存的大小最终收敛到总缓存大小的 19% 和 80%。在不同的负载设置下,Block、KP 和 KV 缓存会稳定成不同的比例
- Ac-Key 是自适应的,可以根据工作负载调整缓存组件的大小。我们还运行离线方案,它试图找到最佳的固定大小的配置。但这种一应俱全的配置并不是针对各阶段的特殊工作负载,因此各阶段的性能都不如ac-key: ac-key 在范围查询阶段比 offline 32%~66%,收敛后在点查找阶段比 offline 好2% ~ 20%(图12下图)。
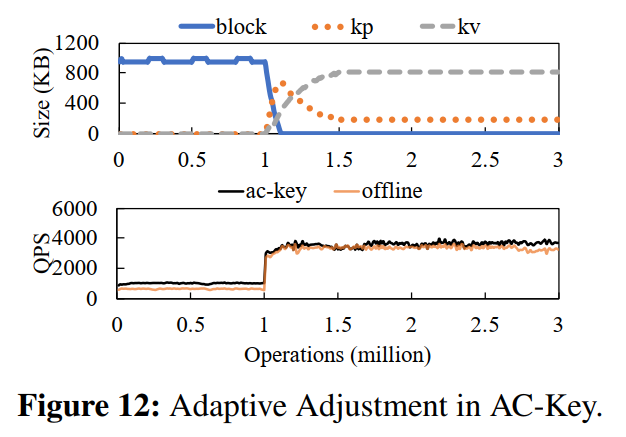
Macro-benchmark YCSB Evaluation
- 我们还在YCSB[15]中使用6个工作负载来进一步验证我们的设计在接近生产的工作负载下的性能。从图13中可以看出,ac-key整体QPS高于rocksdb(提高3.6% ~ 59.9%)、pure-kv(提高0.1% ~ 20.7%)、pure-kp(提高1.2% ~ 25.2%)。
- 我们还测量了RocksDB 的 AC-Key 写入性能的回归(表2),发现回归低于 5%。这表明,在提高整体性能的同时,ac-key不会对写操作产生显著的开销。
Sensitivity on Parameters
- 使用 5.1 中的默认设置,我们在自适应算法(见4.3)中将学习速率 k 的范围从 1K 到 10M,即(1K, 10K, 100K, 1M, 10M)。QPS的波动范围为 3.9%,波动范围为1461 ~ 1520个操作/s。我们还从 0%、5%、···、30% 测试了 ghost 缓存关闭阈值 q (4.3.3), QPS几乎保持不变(1418~1459,在2.8%范围内变化)。由于这两个参数对结果没有显著影响,我们将它们的默认值设置为 k = 100K 和 q = 5
Conclusion
- 缓存是提高基于lsm树的键值存储的读性能的基本技术之一。我们研究了三种不同类型的缓存项,即block、KV和KP,并将它们合并到一个集成的缓存中。我们提出了一种分层自适应缓存(HAC)方案来动态调整块、KV和KP缓存组件的大小。为了处理缓存条目的异构成本和收益,我们利用了一种新的缓存效率因子来帮助缓存组件之间的大小调整和每个缓存组件内的退出决策。我们通过修改RocksDB来实现所提出的 AC-Key。评估结果表明,AC-Key使默认RocksDB的读性能提高了57.1%,而对写性能没有太大影响。
个人总结
- 其实 AC-Key 最大的亮点在于两个点:
- 混合了 KV/KP/Block 三种粒度的缓存
- 三种缓存使用类似于 ARC 的方法,考虑到不同粒度的缓存收益成本模型来作淘汰决策(但其实对比于 offline 的优化效果是很有限的,反而引入了很复杂的决策机制和开销)
- Utterance
