ICDE’20 TKDE’22 UniKV
2023-2-20|2023-3-14
DieInADream
type
status
date
slug
summary
tags
category
icon
password
Property
Mar 14, 2023 07:33 AM
- ICDE20 UniKV: Toward High-Performance and Scalable KV Storage in Mixed Workloads via Unified Indexing
- TKDE’22 The Design and Implementation of UniKV for Mixed Key-Value Storage Workloads
以往方案
FloDB
- 立足的问题:LSM 不能随着内存大小的增加、线程数的增加而方便地扩展,性能提升有限。(其实就是在说SCALABLITY的问题)
- 解决方案:内存组件上加一个小的内存缓冲层,SkipList 的基础上加一个 HASHTable,都是并发的数据结构,都可以并行执行相关操作,FloDB 还对有序数据结构跳表的并发插入操作进行了优化。然后对 scan 操作进行了优化,scan 必然在该场景下是一个很耗时费力的操作。
- 跳表的优化则是并发插入时利用路径重用的思想,减少遍历的次数。利用哈希表分区来尽可能让键之间的距离更小,从而路径重用的效果更好。
- 本文性能测试表明该方案主要针对写操作比较有效,因为读操作大概率还是在磁盘组件上命中,内存组件对写的优化效果更好。
- 所以这个方案的问题一方面是内存开销,另一方面是没有实质解决 LSM 磁盘组件上的性能问题,所以性能其实一般,特别是读操作
Accordion
- 立足的问题:频繁的 compaction 对性能影响太大,大内存场景下以往的内存组件的数据组织效率较低
- 解决办法:内存组件划分为多个层次,划分为多个组件,在内存中就执行一些合并和 GC 操作来把大量的读取写入在内存中吸收,最后将数据写入到磁盘上,来减少在磁盘上进行的 compaction 操作,然后还优化了内存分配上的一些问题,主要是针对 Java JVM 上的分配和 GC 做了一些优化。
- 这个主要还是需要大内存才能实现比较好的效果,而且内存中数据越多,也就意味着 WAL 也就越长,恢复起来越慢,所以故障恢复的效率会是个问题 但随着数据规模的增加,读最终都是要落在磁盘上的,所以该方案在大规模数据的场景下读性能表现也不会太好。
本文的方案 UniKV
- 立足的问题:R/W/SCAN/SCALABLITY 四个维度同时的提升
- 解决方案:内存组件不动,只是在内存中加一个哈希表。在磁盘组件上做变动,把原本的 LSM 上的磁盘组件结构换成两级结构,上层无序存储,下层有序存储。因为上层是内存刷回,所以仅保证文件内有序,而文件间无序,使用一个内存哈希表来所以无序层上的数据。无序层数据达到一定的阈值之后执行合并,并进行 KV 分离来变成有序层,即有序层本质是 Key 有序,而 value 无序,有序层为单层结构,全局有序,从无序到有序的合并过程可能涉及大量的 SSTables,所以用了一个分区来划分,但是分区的粒度是从整个两层结构的基础上进行分区的,即每个分区都有两层结构。
- 减小读写放大的几个措施:
- 无序层的非全局有序,HASH 直接索引
- 有序层 KV 分离,仅 Key 参与排序
- 两层结构整体分区,划分键范围,减小参与合并的数据量
- 因为核心还是有 KV 分离,大量数据分离之后的 scan 必然很差,所以采取了一定程度的优化,一个是无序层上的 scan 优化,主要就是将无序层变为有序层,适当地提高对应层次的有序性来提升 scan。其他的就是一些无关痛痒的优化了,比如 SSD 内部并行性、预取之类的。
- 存在的问题:
- 虽然优化了 scan 但还是很差,比 LevelDB 还差。
- 因为加了内存索引,一定程度增加了内存开销和故障恢复时间
Abstract
- 现有的 KV 存储有严重的读写放大问题,现有设计通常都是在做一些 R/W/SCAN 的权衡,很难同时实现比较高的性能。
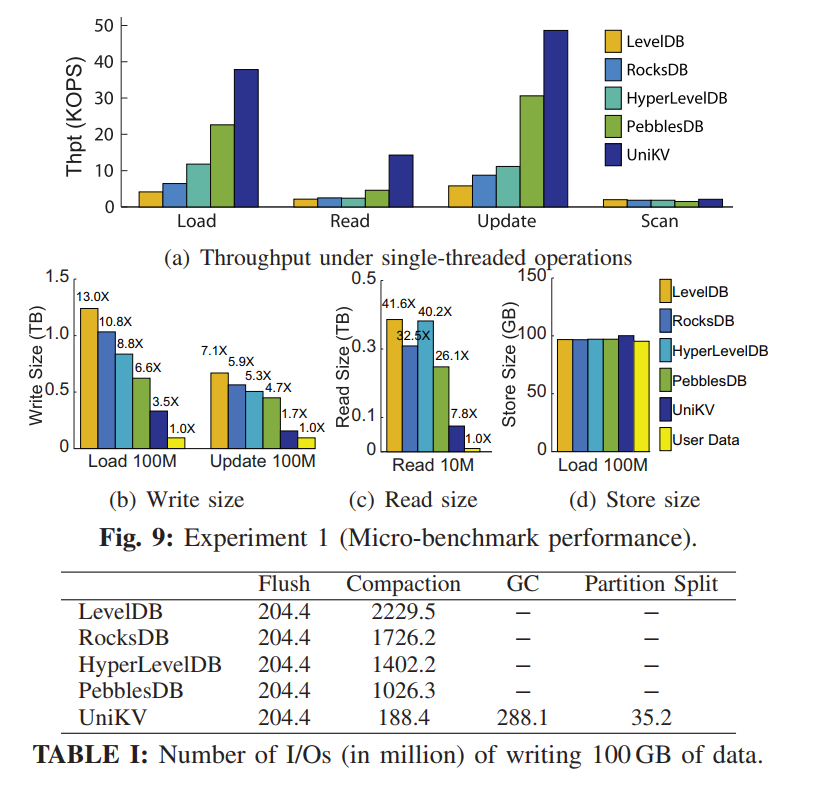
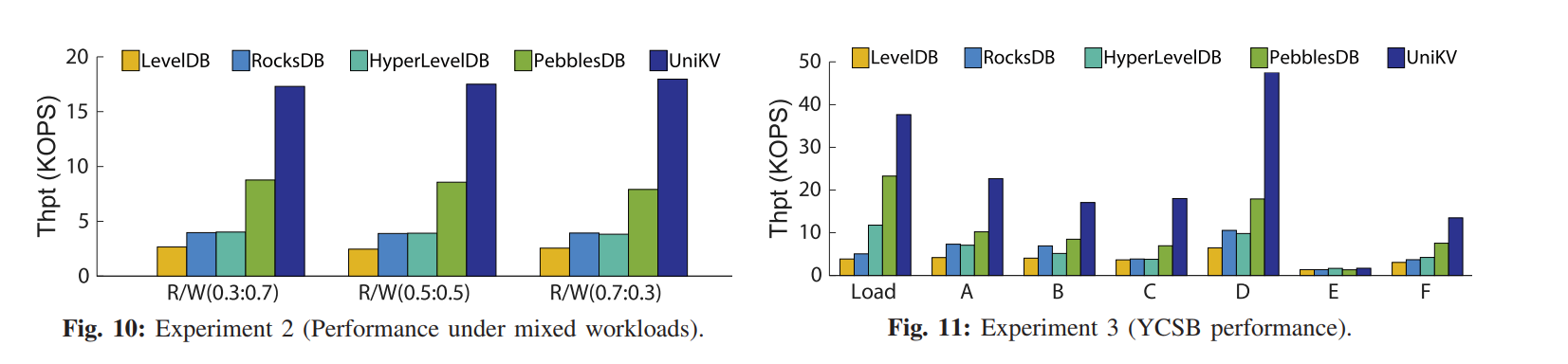
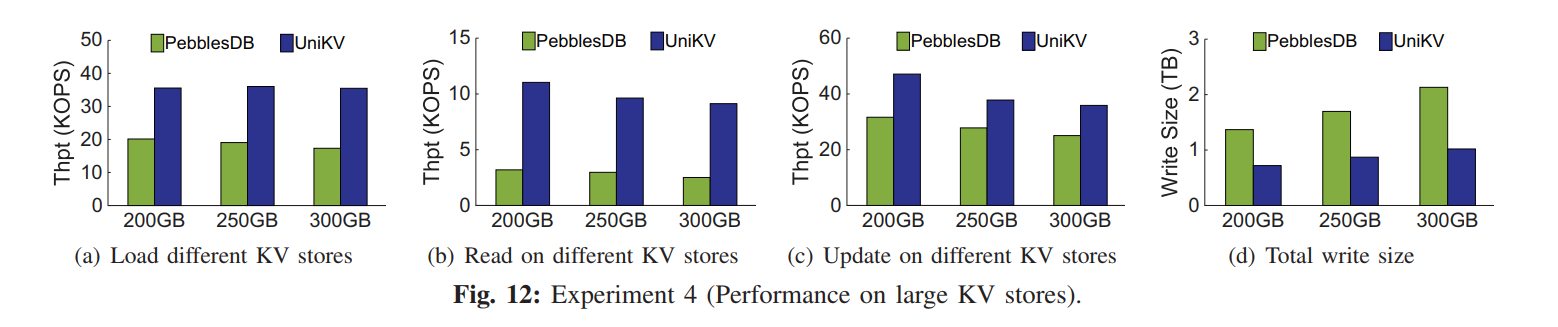
- 本文设计的 UniKV,结合了 HASH 索引和 LSM Tree,利用数据局部性来区分 KV 对的索引管理,它还开发了多种技术来解决统一索引技术引起的问题,从而同时提高读、写和扫描的性能。实验表明,UniKV 在读写混合工作负载下的总吞吐量显著优于几个最先进的 KV 存储(例如,LevelDB、RocksDB、HyperLevelDB 和 PebblesDB)
Intro
- 许多学术和工业项目已经改进了KV存储的 LSM 树的使用,以解决不同的性能方面和存储架构。
- 新的 LSM 树组织:LSM-trie (像前缀树一样的结构),FLSM(分段 LSM 树),KV 分离
- 但是基于 LSM 的索引结构依然很大,这些设计通常都是有取舍的
- LSM-trie 不支持范围查询,来提升读写性能
- PebblesDB 放松了全局有序的限制,牺牲了读性能
- KV 分离引入了额外的查询开销,即需要先查询键,再根据键查询 value
- KV 存储的全部性能潜力仍然受到固有的基于多层的 LSM 树设计的限制
- 我们的见解是,哈希索引是一种经过充分研究的索引技术,它支持特定KV对的快速查找。然而,将散列索引和LSM-tree组合起来是具有挑战性的,因为它们每个都要做出不同的设计权衡。HASH 支持高性能读写,但是不支持 range,同时 HASH 索引保存在内存中,额外的内存开销也就导致了伸缩性的问题。而 LSM 是同时支持高效的写和 scan 的,并同时有良好的可扩展性,但是有比较严重的 compaction 开销和多层访问的开销。因此我们提出了问题:我们是否可以整合 HASH 和 LSM 来同时保证 read/write/scan/Scalability 的高效?
- 现有 KV 负载常有数据局部性,也就给上述问题的解决提供了机会。UniKV 采用分层体系结构实现差异化数据索引,给最近写入的数据(可能会频繁访问的数据,即热数据)构建轻量级内存哈希索引,而维护大量的不频繁访问的数据(也就是冷数据)在一个完全有序的基于 LSM 的设计中。
- 为了高效利用 HASH 索引和 LSM 树而不用导致大量的内存和 I/O 开销,UniKV 设计了三种技术:
- 轻量级的两级 HASH 索引来保证内存开销尽可能小,同时加速热数据的访问
- 为了减少热KV对迁移到冷KV对引起的I/O开销,UniKV 设计了部分KV分离策略来优化迁移过程
- 为了在 大 KV 存储中实现高扩展性和高效的读写性能,UniKV 不像传统的基于 lsm 树的设计那样,允许冷 KV 对之间有多个级别;相反,它采用了一种横向扩展(scale-out)方法,通过动态范围分区方案将数据动态地分割为多个独立的分区。
BACKGROUND AND MOTIVATION
- 背景方面主要介绍了造成 LSM 读写放大的原因:
- 写放大:compaction 读后排序覆盖写
- 读放大:L0 无序全量检索,一层一层地进行检索,BloomFilter 误报

- Motivation:
- 内存哈希索引:内存 HASH 索引查询性能高,直接使用 HASH 函数计算就能找到对应的 pointer,然后根据 pointer 就能取出对应的数据。写性能也很高,虽然可能产生 HASH 冲突,但也有一些 HASH 冲突的解决办法。
- 设计 tradeoffs:HASH 索引和 LSM 其实是在 R/W/扩展性 三个方面做了不同的权衡,
- HASH 索引的读写较好,但是有一些限制
- 扩展性较差,对于大数量的 KV 存储,读写性能可能显著下降因为哈希冲突和有限的内存,性能可能比 LSM 还差。为了证明该结论,使用了基于 HASH 索引的 SkimpyStash 来和 LevelDB 对比
- 除此以外,HASH 索引不支持高效的范围查询
- LSM 支持大量的数据存储而不使用额外的内存索引,在大数据量场景下比 HASH 表现更好,然后有着很严峻的读写放大问题,虽然有大量的方案在优化这一点,但是本质都是在 R/W 之间做 trade-off。
- 负载特征: 真实 KV 负载不仅仅是读写混合的,还有很强的数据访问倾斜性,即一小部分数据可能需要接受大量的请求。该结论也进行了实验证明,下图展示了 SSTable 的访问频率。X 轴代表了从低到高 Level 顺序编号的 SSTable,Y 轴代表每个 SSTable 的访问次数。平均来讲,更低 Level 的 SSTables 也就是更小 ID 的 SSTables 通常刚从内存中刷回,相比于更高层的 Table 有更高的访问频率。最后一层包含大约 70% 的 SSTables,但是他们只接受 9% 的请求。
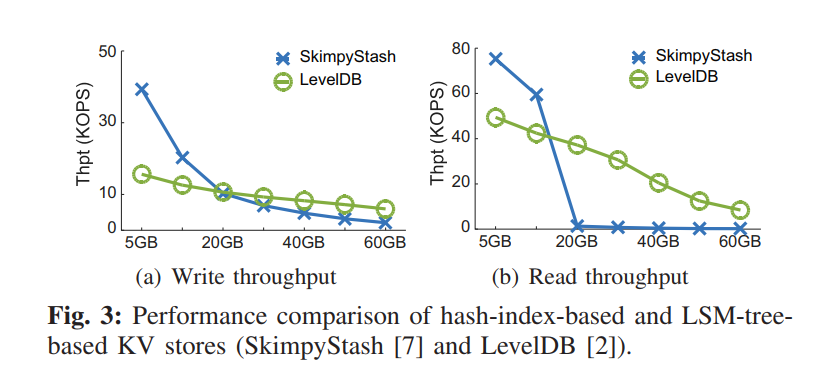
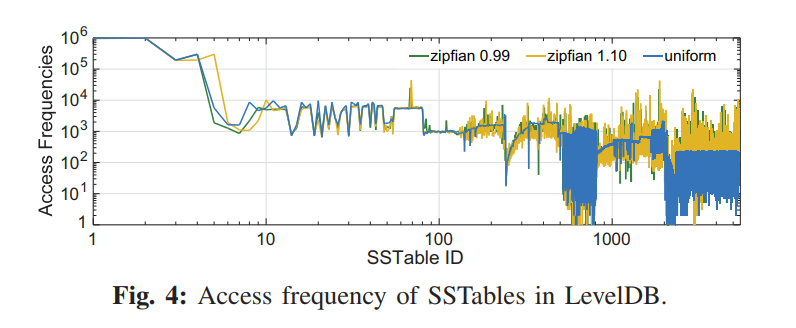
- Main Idea:基于 HASH 和 LSM 各自设计的 trade-off,以及负载局部性的事实,我们的思想就是结合 HASH 索引和 LSM 来解决各自的限制。
- 具体来讲,就是使用 HASH 索引来加速单个 Key 的查询,通常是很小比例的经常访问的数据,也就是热数据。
- 与此同时,对于大量的不常访问的冷数据,我们仍然遵循原始的 LSM 设计来提供较高的 scan 性能。
- 同时为了支持大数据量的存储的可扩展性,我们提出了动态范围分区的方法来以 scale out 的形式扩展 LSM。
Design
架构概览
- 两层结构:
- 第一层为 UnsortedStore,保存了从内存刷回的数据,无序。
- 第二层为 Sorted Store,保存了从 Unsorted Store 合并后的有序的数据
- 利用数据的局部性,小比例的热数据保存在 UnsortedStore 中,直接使用一个内存 HASH 索引来支持快速的读写,同时保证剩余数量的冷数据在 SortedStore 中,以有序的形式来提供高效的 scan 和更好的扩展性。
- 使用了如下技术:
- Differentiated indexing:两层使用不同的索引
- Partial KV separation:部分 KV 分离来优化两层之间的 Merge
- Dynamic range partitioning:动态范围分区来以 scale out 的形式扩展存储
- Scan optimizations and consistency:优化了 scan 和 crash recovery 的实现
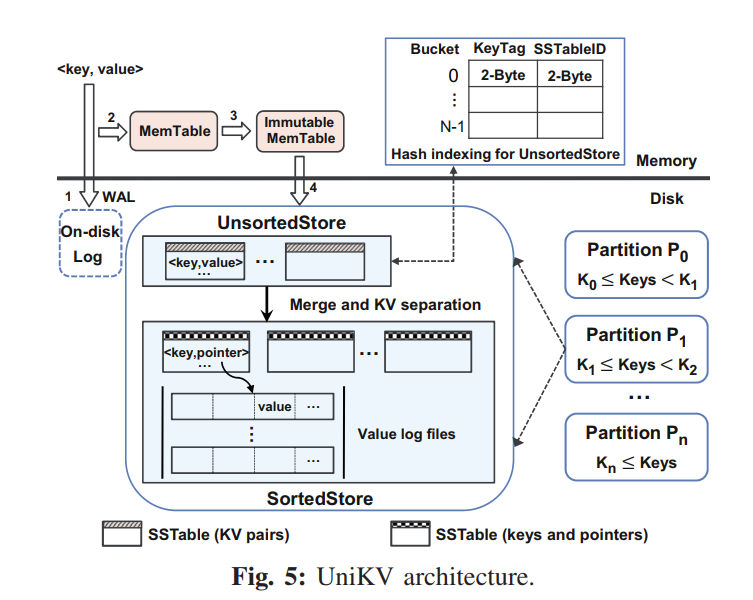
Differentiated Indexing
Data Management
- 第一层直接追加写,无需有序,内存 HASH 表索引,从而快速查询。第二层在 LSM 中组织,Key 全局有序,KV 分离,Value 存储在单独的 Value Log。LSM 中存储 Key 和 Address。
- 移除了所有 SSTables 的 BloomFilters 来节省内存空间并减少计算开销。对于 UnsortedStore 中的数据直接使用内存 HASH 表就能查询到对应 Key 的位置信息,对于 SortedStore 中的数据,我们也可以有效地找到可能包含 KV 对的SSTable,通过二分搜索,比较 SSTable 的键和存储在内存中的边界键,因为所有的键在 SotedStore 中有序。即便是查询不存在的键,也只会访问一个 SSTable,这只会增加一个额外不必要的从 SSTable 的 I/O 读取来确认不存在的 Key,因为我们可以通过使用索引块的元数据来直接决定 SSTable 哪个数据块内(通常是4KB) 需要读出,元数据又通常是缓存在内存中的。相比之下,现有的基于 LSM 树的 KV 存储可能需要对 SSTable 进行 7.6 次检查,由于 Bloom 过滤器的误报以及多层搜索,平均需要 2.3 次 I/O 才能进行键查找。
- 对于内存中的数据管理,UniKV 使用和传统 LSM 相似的方式,同时使用 WAL 确保数据的可靠性,KV 首先写入到磁盘上的日志中来保证崩溃一致性,然后插入到 Memtable,也就是对应的一个内存跳表中,Mmetable 满了之后,转换为 Immutable Memtable,然后再刷回到磁盘变成 UnsortedStore 中的一个数据文件,追加写入。
Hash indexing
- UnsortedStore 中的 Tables 以追加写的方式写入,使用内存哈希表索引,为了减小内存开销,我们构建了一个轻量级的两级 HASH,结合布谷鸟 HASH 和链式 HASH 来解决哈希冲突。如下图所示,每个桶存储使用了布谷鸟哈希的 KV 对索引项,所以可能因为哈希冲突而追加好几个 overflowed 的索引项。当我们构建索引项的时候,根据 n 个哈希函数的哈希结果找到对应的桶,直到找到一个空位置,最多使用 n 个哈希函数,如果不能在 n 个桶中找到对应的空桶,生成一个 overflowed 的索引追加到对应的桶后
- 定位到桶之后,记录 KeyTag 和 SSTableID 到对应的索引项中,每个索引项包含三个信息 <keyTag, SSTableID, pointer>,keyTag 保存使用了不同的 HASH 函数计算出的哈希值的高位 2 Bytes,被用来在查询过程中快速过滤出索引项。使用 2Bytes 来存储 SSTable ID,如果 UnsortedStore 中一个 SSTable 2MB,那么我们可以索引 128GB (2^16 * 2MB) 的数据。指针使用了 4Bytes 来指向相同 Bucket 的下一个索引项。
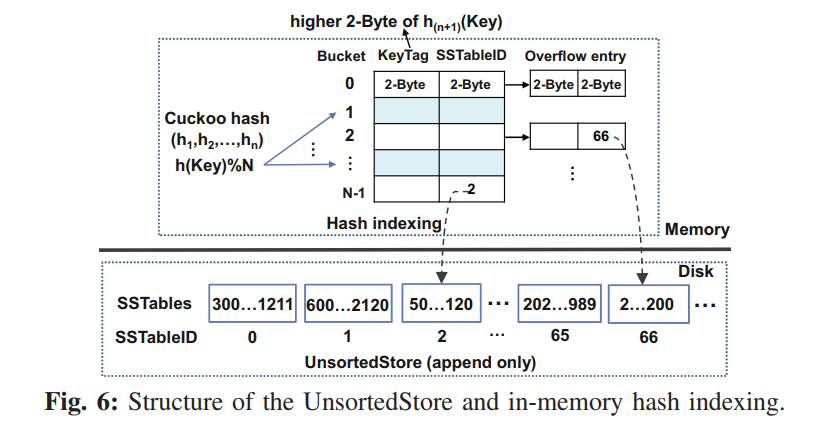
Key Lookup
- 键查询过程如下:
- 使用 计算 KeyTag,搜索候选的 buckets 从 到 ,直到找到了 KV 对,对于每一个候选的 Bucket,因为最新的 overflow 项被追加到了其尾部,因此,我们将 keyTag 与属于这个 bucket 的 overflow 索引项从尾部开始进行比较,一旦找到了匹配的 keyTag,就根据对应的 SSTableID 检索出 SSTable 对应的元数据信息,并读出对应的 KV 对,注意查询的 KV 对可能因为哈希冲突而不存在于这个 SSTable (因为可能不同的 key 有相同的 tag),然后我们继续查询候选的 buckets,最终,如果 KV 对在 UnsortedStore 中没找到,那我们就从 SortedStore 上通过二分查找去找。
- 哈希冲突的话对应的查询复杂度就变高了,因为可能涉及到多次检索哈希表和检索 SST 的操作
Memory overhead
- 我们分析了哈希索引的内存开销,UnsortedStore 中的每一个 KV 对消耗一个索引项,每个索引项消耗 8B 的内存,因此 UnsortedStore 中的每 1GB 数据,每个 KV 项 1KB 的话,将有大约 100w 索引项,消耗大约 10M 内存(在给定 Bucket 利用率大约为 80% 的情况下),内存的使用量小于 UnsortedStore 的数据大小的 1%。对于特别小的 KV 对,哈希索引可能导致较大的内存开销,一个解决方案就是差异化不同大小的 KV 项的索引的管理,例如对于小 KV 则使用经典的 LSM,对于大 KV 则使用 UniKV。
- 我们的哈希索引在设计上做了一个 trade-off
- 一方面,哈希冲突可能当我们分配 Buckets 给 KV 对时存在,因此我们需要在索引项中存储 Key 的信息以便在查询过程中区分。
- 另一方面,存储完整的 Key 浪费了内存,为了平衡内存消耗和读性能,UniKV 使用了两位来保留 HASH 值的 2B 作为 keyTag,从而显著减少了哈希冲突的概率。如果哈希冲突发生了,也可以通过比较存储在磁盘上的键来解决。
Partial KV separation
- 因为 UnsortedStore 的 KV 对使用了内存哈希表来索引,引入了额外的内存开销。对应的 SSTables 的键的范围因为只能追加写的策略变得可能范围重叠,所以执行 scan 的时候不可避免地需要检索每个 SSTable。为了限制内存开销并保证 scan 性能,UniKV 限制了 UnsortedStore 的大小,当大小达到设定阈值 UnsortedLimit 时,UniKV 触发一个合并操作,从 UnsortedStore 合并到 SortedStore,该参数根据可用内存来配置。
- 合并操作可能产生大的 I/O 开销,因为 SortedStore 现有的 KV 对需要先读取然后合并排序后写回,因此如何减少合并开销是关键且有挑战性的。
- UniKV 提出了一个部分 KV 分离的策略,在 UnsortedStore 中不分离地保存,但是在 SortedStore 中分离保存。
- 基本原理就是从内存中最近刷回的保存在 UnsortedStore 的数据因为局部性的原因更有可能是热数据,因此为了高效访问 KV 存储在了一起,然而 SortedStore 中的 KV 数据更可能是冷数据,因此数据量非常大,造成很大的合并开销。因此我们采用了 KV 分离来减少合并的开销。
- 下图描绘了该设计思路,当从 UnsortedStore 合并到 SortedStore 的时候
- UniKV 批量合并 Keys,同时保存 value 到一个新的创建的追加写的日志文件中
- 还使用指针记录值位置,这些指针与相应的键保存在一起,每一个指针项包含四个属性:<partition,logNumber,offset,length> 分别代表 partition number,log file id, value location, length。
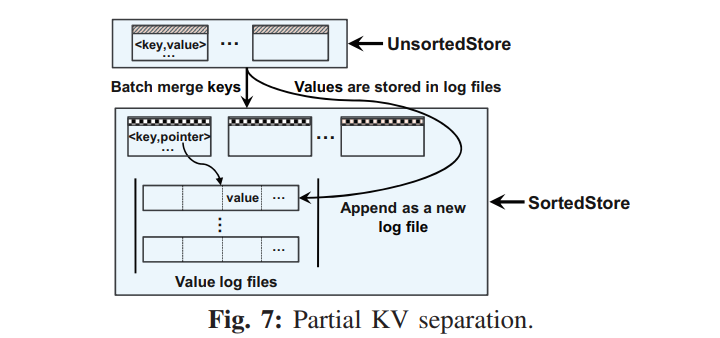
- 其实这里可以考虑直接不做合并,直接把 UnsortedStore 中存储的一个个数据表当成一个个 Log,需要回收的 value 数据交给 GC,合并操作就完全只是一个角色的转变,顶多有元数据的修改,而不涉及任何的 I/O,从而减小两层之间的合并开销
Garbage collection (GC) in SortedStore
- SSTable 中的无效 Keys 在 Compaction 的时候会被删除,所以这里的 GC 是指删除 Value Log 中的无效 Values。
- GC 以日志文件为单元进行操作,当一个分区的大小超过预定义阈值的时候触发 GC,具体而言就是 GC 操作首先从日志文件的分区中识别并读出所有的有效值,然后把所有的有效值写回到一个新的日志文件,并生成新的指针来记录最新的 value 位置信息,最后删除无效的指针和老旧的文件。
- 有两个关键问题:
- 哪些分区被选择来 GC?
- 如何从日志文件中快速识别出有效的值并读取?
- 不像之前的 KV 分离方案 WiscKey 一样严格按顺序执行 GC,UniKV 可以灵活地选择任意分区执行 GC 因为 KV 根据键范围被映射到了不同的分区而且分区之间的操作互相独立。
- 作者采用了一个贪心方法来选择有最大数量的 KV 的分区来 GC,同时检查选择的分区的日志文件中的 value 的有效性
- UniKV 只需要检查保存了有效的 Key 和最近的位置信息的 SortedStore 中的 Keys 和指针,因此对于每个 GC 操作只需要扫描 SortedStore 中的所有 Keys 和指针来获取所有的有效值,花费的时间主要取决于当前 SortedStore 中 SSTables 的总大小
- 注意 GC 和 compaction 操作是顺序执行的,所以 GC 操作也发生在数据加载的过程中,并且在度量写性能时还计算了 GC 成本。
Dynamic Range Partitioning
- 因为 SortedStore 随着数据量逐渐变大,如果只是像 LSM 在大规模的存储中简单地添加更多的层次,将会导致频繁的合并操作,相应地在写数据时将数据从低向高移动,读数据时触发多层访问。每个 GC 需要通过查询 LSM 从日志文件中读取所有的有效的数据并写回,所以 GC 的开销也会随着层级的增加变得很大。因此 UniKV 提出了动态范围分区的方法来以 scale out 形式扩展,该方法把不同范围的 KV 映射到独立管理的不同分区,每个分区有自己的 UnsortedStore 和 SortedStore。
- 工作原理如下图所示,初始地,UniKV 在一个分区写数据,一旦大小达到阈值,partitionSizeLimit,UniKV 就把分区根据范围平均分成两个分区,对于范围分区,关键特性是两个新分区的键不应该有重叠。为了实现这一点,UnsortedStore 和 SortedStore 中的 KV 对都需要被拆分。

- 为了分割 UnsortedStore 和 SortedStore 中的键,UniKV 首先锁住它们并暂停写请求。注意,锁粒度是一个分区,也就是说,UniKV 锁住整个分区,并在分割期间暂停对这个分区的所有写入。然后对所有键进行排序,以避免分区之间的重叠。
- 它首先将所有内存中的 KV 对刷新到 UnsortedStore 中,并读取 UnsortedStore 和 SortedStore 中的所有 sstable 来执行合并排序,就像在基于 lsm 树的 KV 存储中一样。
- 这里涉及到一个问题:对于 SortedStore 的读取需要专门进行一次 I/O 读取相应的 value,然后再写回,开销看起来不小。
- 然后将排序后的键分成等量的两部分,并记录两部分之间的边界键 K。注意,这个边界键 K 作为分裂点。也就是说,键小于 K 的 KV 对形成一个分区 P1,其他的则形成另一个分区 P2。通过分隔点,UniKV 将 UnsortedStore 中的有效值分成两部分,并通过将它们附加到每个分区新创建的日志文件中,将它们写到相应的分区中。
- 最后,UniKV 将值位置存储在指针中,这些指针与对应的键保存在一起,并将所有键和指针写回对应分区中的 SortedStore。
- 注意 UniKV 释放锁,并在键分割后恢复处理写请求。
- 其次,为了拆分 SortedStore 中的值(这些值分别存储在多个日志文件中),UniKV 采用了一个惰性拆分方案,该方案在使用后台线程进行 GC 期间拆分日志文件中的值。它的工作原理如下。
- P1 中的 GC 线程首先扫描 P1 的 SortedStore 中的所有 sstable。
- 然后,它从 P1 和 P2 共享的旧日志文件中读出有效值,并将它们写回属于 P1 的新创建的日志文件。
- 最后,它生成新的指针,这些指针存储有相应的键,以记录值的最新位置。
- P2 中的 GC 线程执行与 P1 中相同的过程。
- 惰性拆分设计的主要好处是通过将其与 GC 操作集成在一起来显著减少拆分开销,从而避免较大的 I/O 开销。注意,对于范围分区,P2 中的最小键必须大于 P1 中的所有键。一旦一个分区达到其大小限制,这个范围分区过程就会重复。我们强调,每个分割操作都可以看作是一个压缩 Compaction 操作加上一个 GC 操作,但是它们必须按顺序执行。因此,在分区中分割键会引入额外的 I/O。分割后,每个分区都有自己的 UnsortedStore、SortedStore 和日志文件。
- 对于大型KV存储,初始分区可能会分裂多次,从而产生多个分区。为了在进行读写操作时有效地定位某个分区,我们在内存中记录每个分区的分区号和边界键,作为分区索引。我们还持久化地将分区索引存储在磁盘上的 manifest 中。另外,不同分区的键没有重叠,所以每个键只能存在于一个分区中。因此,可以通过首先定位一个分区来执行键查找,这可以通过检查边界键来有效地完成,然后只查询一个分区内的 KV 对。简而言之,动态范围分区方案通过将KV 对拆分为多个独立分区,以横向扩展 scale-out 的方式扩展存储。因此,该方案可以保证较高的读写性能,以及高效的扫描,即使是大型 KV 存储,使其具有良好的可扩展性
I/O Cost Analysis
- 此处省略。原文分别分析了传统 LSM 和 UniKV 各自的读写开销。UniKV 相比之下开销更小。
期刊:Parallel Optimization(会议没有)
- 因为拆分产生了多个分区,所以可以并行读写请求处理。
- 如下图所示提出了一个多队列方案,每个分区维护一个队列,请求首先分发到各个队列,队列满了则挂起接受请求的线程,直到队列有足够的空闲空间。
- 并发处理机制和 LevelDB 的锁方案类似。请求调度到某个分区,则先对该分区加锁,然后把请求丢到内存中的队列中去,然后释放锁。对于请求队列中的请求,UniKV 使用一个后台线程来获取请求并按照 FIFO 的顺序执行。
- 区别于 LevelDB 的全局队列,UniKV 是每个分区都有一个队列,因此可以完全分区间并行执行,每个分区有个专门的队列和专门的线程。
- 然后做了一个并行方案的理论计算分析。

Scan Optimization
- 因为 KV 在 UniKV 的 SortedStore 中是分开存储的,所以 scan 操作可能会对 value 造成随机读。而 UnsortedStore 中的 SSTables 本身又是直接从内存刷回的所以是无序的,其键范围是重叠的,scan 操作可能就会读取每个 SSTable,因此也会造成额外的读开销。
- 为了优化 scan,UniKV 首先通过快速的查询分区键的边界来快速找到要 scan 的键对应的分区,可能会显著减少需要 scan 的数据量,UniKV 还使用了一些其他策略。
- 对于 UnsortedStore,UniKV 提出了一个 Size-based Merge 策略,即把 Unsorted Store 中的所有 SSTables 合并成一个大的 SSTable,使用一个后台线程来保证数据全局有序,该线程只有当 UnsortedStore 中的 SSTables 数量达到预定义的阈值 scanMergeLimit 时的才会执行。即便该操作会造成额外的 I/O 开销,如果 UnsortedStore 的大小是有限的话,该操作的 I/O 开销也会很小。该操作可以显著提升 scan 的性能因为高效的顺序读,特别是大数据量的 scan 操作。
- 对于 SortedStore,UniKV 利用 SSD 的 I/O 并行性来从日志文件中多线程并发获取 values。UniKV 还利用预读机制来预取 values 到 page cache,工作流程如下:
- 首先从 SortedStore 中的 SSTables 获取给定 scan range 内的 keys 和 pointers
- 然后以第一个键的值开始向日志文件发出预读请求(via posix_fadvise)
- 最后根据指针读取出 values 并返回 KV 对。
- 另一方面我们认为 UniKV 不会对 UnsortedStore 和 SortedStore 的扫描结果执行内存合并和排序,这是因为一个 scan 操作是通过如下三步执行的:
- seek() 它从每个需要检查在 UnsortedStore 和 SortedStore的sstable 中定位开始键,并返回初始键的 KV 对直到找到
- next() 找到比需要检查的每个 sstable 中最后一个返回的键大的下一个最小键,并返回最小键的值
- 重复步骤二直到返回的 KV 对的数量等于 scan 的长度
- 通过上述优化,我们的实验表明 UniKV 的扫描性能与 LevelDB 相似,后者总是保持键在每个级别上的完全排序。
AIO for the SortedStore(期刊版本)
- 键值对在有序层单独存储,scan 操作导致随机访问。虽然多线程可以加速读取,但是引入了更多的 CPU 开销
- 异步非阻塞 I/O AIO 有更好的性能,且是单线程。所以 UniKV 为了避免有限 CPU 资源下的消耗,使用了 AIO 加速有序层的访问。
- 首先 seek 找到第一个键值对,如果值是一个 KP,发起一个 AIO 来获取值,否则直接返回键值对
- 最后等待所有的 AIO 完成
- UniKV 可以在执行一系列next()时并发地对日志文件发起多次随机读取,因此扫描性能显著提高。此外,AIO是通过单个线程执行的,因此即使在有限的CPU资源下也能实现高扫描性能
Crash Consistency
- 三个地方需要保证崩溃一致性:Memtables 中缓冲的数据,内存哈希索引,SortedStore 的 GC。对于 KV 对直接使用 WAL 来保证,关于分区的元数据信息直接使用 manifest 来保证,一样也是 WAL 机制。
- 内存哈希表则使用 checkpointing 技术,当每一半的 UnsortedLimit sstable 从内存刷新到 UnsortedStore 时,它将哈希索引保存在磁盘文件中,因此重建哈希索引可以通过读最近保存的磁盘上的索引的副本来 replay。
- GC 操作的一致性保证不太一样,因为需要重写现有的有效 KV 对,为了保证现有的有效的 KV 对的一致性,执行以下步骤:
- 识别出有效 KV 对
- 读取有效的 values 并写回到新的 log file
- 写所有的新的指向新的日志文件的指针和对应的 Key 到 SortedStore 的 SSTable 中
- 标记新的 SSTable 为有效,以 GC_done 的标志标记老的日志文件来允许其被删除
- 如果 crash,可以根据上面四个步骤 redo GC
- UniKV 实现了上述机制,实验表明恢复开销很小。
Implementation Issues
- 基于 LevelDB v1.20 实现,修改了大约 8K 代码,大部分都是为了引入哈希索引、动态范围分区和部分 KV 分离、以及 GC 操作。因为 UnsortedStore 和 SortedStore 都是基于 SSTable 的,所以 UniKV 可以直接利用 SSTable 成熟稳定的代码。
- 对于 scan,UniKV 利用了多线程技术来并发获取 values。然而线程数量受限于一个进程的内存空间大小,使用太多线程可能触发频繁的上下文切换,UniKV 维护了一个 32 线程的线程池并从池中并行地分配线程来获取 values。Scan 过程中,UniKV 插入固定数量的 value 地址到 worker queue 中,然后可以唤醒睡眠线程来并行第读取 value。
Related Work
- HASH 索引:
- VLDB10 Flashstore / SIGMOD’11 Skimpystash / SOSP’09 Fawn 维护了内存哈希索引,存储了 Key 签名和执行存储在磁盘上的 KV 对的指针。有很多在哈希索引上的优化,比如基于页访问的 VLDB13 LLAMA,基于日志存储和多版本索引的 VLDB12 LogBase,用于并行访问的有损和无损哈希索引 NSDI14 MICA。EuroSys17 FloDB 的内存哈希表。但是哈希索引仍然有较差的扩展性且不支持高效的 scan。
- LSM-tree:
- 许多基于 LSM 构建的持久化存储解决了扫描操作和扩展性的问题。先前的研究主要聚焦于提升 LSM 设计的写性能,包括:
- HyperLevelDB 的细粒度锁,
- RocksDB / Eurosys14 An efficient design and implementation of lsm-tree based key-value store on open-channel ssd / EuroSys’15 Scaling concurrent log-structured data stores 关于并发和并行的优化,
- SIGMOD12 bLSM / FAST13 VT-tree 对 compaction 开销的减小
- ATC15 LSM-trie / SOSP17 PebblesDB 优化的 LSM 结构
- ATC17 TRIAD 热点感知
- FAST16 WiscKey / ATC18 HashKV / FAST16 “Efficient and available in-memory kv-store with hybrid erasure coding and replication 的 KV 分离
- 一些研究聚焦于提升读性能,包括针对不同层实现不同的布隆过滤器的 Monkey,基于数据局部性的布隆过滤器的弹性内存分配 ElasticBF 以及一种简洁的 trie 结构 SuRF
- 混合索引:
- SILT 结合日志、HASH、有序的 KV 存储并使用压缩哈希表来减小每个 Key 的内存开销
- NV-tree, HiKV, NoveLSM 在 NVM 上设计新的索引结构
- Data Calculator 和 Continuums 聚焦于统一主流的不同数据结构来实现自我驱动设计的 KV 存储
- Utterance
