LevelDB LRUCache
2021-12-19|2023-9-19
DieInADream
type
status
date
slug
summary
tags
category
icon
password
Property
Sep 19, 2023 06:36 AM
References
Cache 整体
- 大多数磁盘数据库都提供了缓存,因为磁盘和内存的访问速度差了好几个数量级。如果整个数据库的工作集小于内存,那么热数据基本都可以缓存到内存里,这时候数据库表现得就像一个内存数据库,读写效率很高。
- 最完美的缓存就是将最近将要使用的数据缓存在内存里。然而,未来的访问数据是比较难估算的,一般会采取一些预读的方案将数据预先读取到内存中。而缓存的策略一般都是LRU,也就是根据过去的访问来决定缓存。遵循这样的原则:最近被访问过的数据未来有很大概率再次被访问。
- LevelDB提供了一个
Cache接口,用户可以实现自己的缓存方式。默认提供了一个 LRU Cache,缓存最近使用的数据。 include/leveldb/cache.hutil/cache.cc
- LevelDB的缓存使用在两个地方:
- BlockCache: 缓存 SSTable 里的 Data Block,也就是缓存数据,数据的缓存不是以 KV 为单位的,而是以Data Block为最小单位进行缓存,默认情况下会开启一个 8MB 的 LRU Cache 来缓存Data Block。考虑到一次扫描可能将所有的内存缓存都刷出去了,LevelDB支持在扫描时,不缓存数据;
- 使用 ReadOptions 的 fill_cache 参数来控制是否缓存数据
- TableCache:缓存 SSTable 在内存中的数据结构Table,一个表在使用前需要先被 Open,被 Open 时会将 SSTable 的元数据,比如 Index Block 和布隆过滤器,读取到内存中。缓存Table时是以个数计算的,缓存的个数是
max_open_files - kNumNonTableCacheFiles,kNumNonTableCacheFiles表示给非SSTable预留的文件描述符数量,为 10。
- 其实还有操作系统/文件系统的 Page Cache,功能和 Block Cache 更为类似,只是 Block Cache 中存放的是未 uncompressed data,而 Page Cache 中是 compressed data。
缓存相关配置
Block Cache
- 可以在 Options 中指定 cache 实现,参数由 options.block_cache 设定,既可改变缓存大小,也可根据自己的应用需求,提供新的缓存策略。注意,此处的大小是未压缩的block大小。
include\leveldb\options.h。如果为空默认为 8MB 的内部缓存
- 还可以设置哪些读是需要放到 cache 中。默认为 true
Cache 接口定义
- 缓存接口定义
- 核心接口:
Insert、Erase、LookUp
Cache 需求
- 多线程支持(使用引用计数)
- 性能需求
- 数据条目的生命周期管理
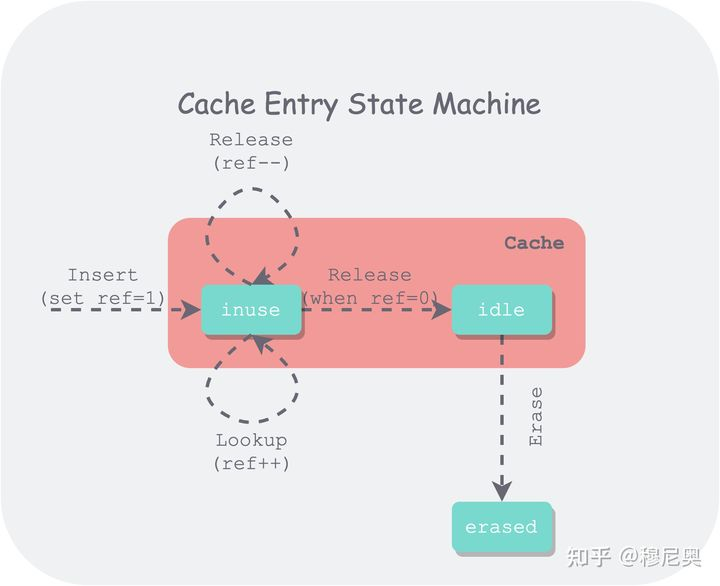
生命周期:
- 多个线程可以通过 Insert、Lookup 对同一个条目进行插入和引用,因此缓存需要维护每个条目(entry)的引用数量。只有引用数量为 0 的条目才会进入一个待驱逐(idle)的状态,将所有待驱逐的条目按 LRU 顺序排序,在用量超过容量时,将依据上述顺序对最久没使用过的条目进行驱逐。
- Insert()/Lookup()之后,会返回对这个内存块的引用Handle*。 本质上就是引用次数++
- 当把Handle使用完毕之后,需要Release()这个Handle。 本质上是对引用次数--。
- 此外,需要进行线程间同步和互斥,以保证 Cache 是线程安全的,最简单的方法是整个 Cache 使用一把锁,但这样多线程间争抢比较严重,会有性能问题。
Cache 接口实现
- leveldb中使用的cache是一种LRUcache,LRUCache 即是一个基于 LRU 淘汰策略的缓存。当热点数据比较集中时,LRUCache 的效率比较高。其结构由两部分内容组成:
- Hash table:用来存储数据;
- LRU:用来维护数据项的新旧信息;
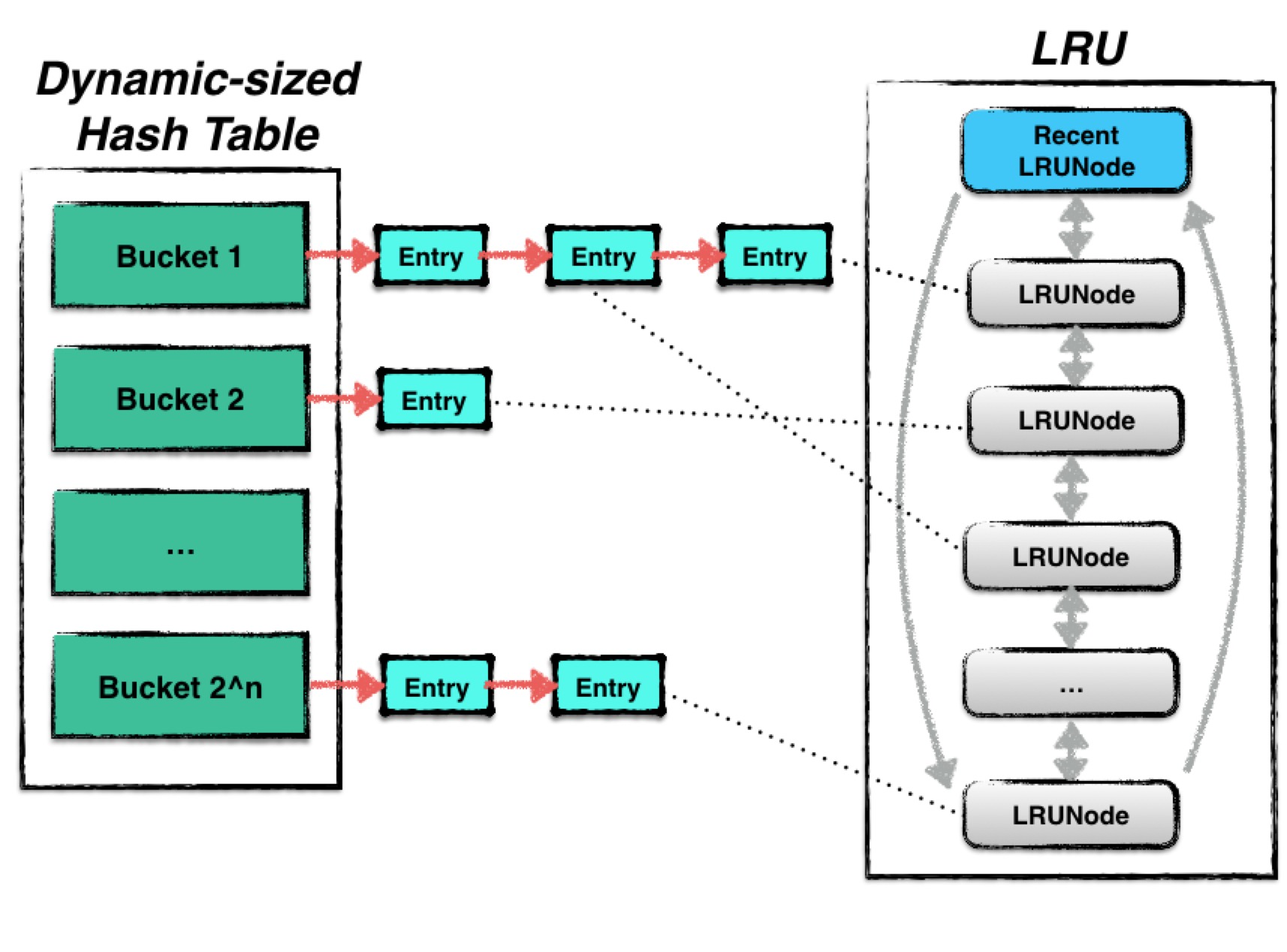
- LevelDB 的 LRUCache 的实现由一个哈希表和两个链表组成:
- 链表 lru_:维护 cache 中的缓存对象的使用热度。数据每次被访问的时候,都会被插入到这个链表最新的地方。 lru_->next 指向最旧的数据, lru_->prev 指向最新的数据。当 cache 占用的内存超过限制时,则从 lru_->next 开始清理数据。
- 链表 in_use_:维护 cache 中有哪些缓存对象被返回给调用端使用。这些数据不能被淘汰。
- 哈希表 table_:保存所有 key -> 缓存对象,用于快速查找数据。
- LRUCache 的 Insert 和 Lookup 的时间复杂度都是 O(1)。
定制哈希表
- LevelDB 中哈希表保持桶的个数为 2 的次幂,从而使用位运算来通过键的哈希值快速计算出桶位置。通过 key 的哈希值来获取桶的句柄方法如下:
- 每次调整时,在扩张时将桶数量增加一倍,在缩减时将桶数量减少一倍,并需要对所有数据条目进行重新分桶。
- 使用位操作来对 key 进行路由,使用链表来处理冲突,实现比较直接。链表中节点是无序的,因此每次查找都需要全链表遍历。
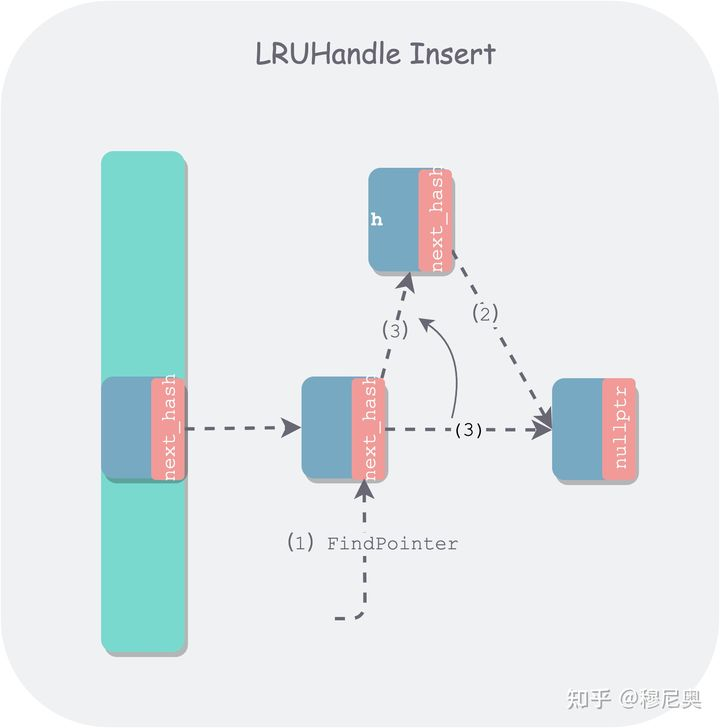
- 其中值得一说的是 FindPointer 这个查找辅助函数,该函数用了双重指针,在增删节点时比较简洁,开始时可能不太好理解。在通常实现中,增删节点时,我们会找其前驱节点。但其实增删只用到了前驱节点中的 next_hash 指针:
- 删除:会修改 next_hash 的指向。
- 新增:首先读取 next_hash,找到下一个链节,将其链到待插入节点后边,然后修改前驱节点 next_hash 指向。
- 由于本质上只涉及到前驱节点 next_hash 指针的读写,因此返回前驱节点 next_hash 指针的指针是一个更简洁的做法
- 由于返回的是其前驱节点 next_hash 的地址,因此在删除时,只需将该 next_hash 改为待删除节点后继节点地址,然后返回待删除节点即可。
- 在插入时,也是利用 FindPointer 函数找到待插入桶的链表尾部节点 next_hash 指针的指针,对于边界条件空桶来说,会找到桶的空头结点。之后需要判断是新插入还是替换,如果替换,则把被替换的旧节点返回,下面是插入新节点示意图:
- 如果是新插入节点,节点总数会变多,如果节点总数多到大于某个阈值后,为了保持哈希表的性能,就需要进行 resize,以增加桶的个数,同时将所有节点进行重新分桶。LevelDB 选定的阈值是 length_ —— 桶的个数。
- resize 的操作比较重,因为需要对所有节点进行重新分桶,而为了保证线程安全,需要加锁,但这会使得哈希表一段时间不能提供服务。当然通过分片已经减小了单个分片中节点的数量,但如果分片不均匀,仍然会比较重。这里有提到一种渐进式的迁移方法:Dynamic-sized NonBlocking Hash table,可以将迁移时间进行均摊,有点类似于 Go GC 的演化。
两个链表
- LevelDB 使用两个双向链表保存数据,缓存中的所有数据要么在一个链表中,要么在另一个链表中,但不可能同时存在于两个链表中。这两个链表分别是:
- in-use 链表。所有正在被客户端使用的数据条目(an kv item)都存在该链表中,该链表是无序的,因为在容量不够时,此链表中的条目是一定不能够被驱逐的,因此也并不需要维持一个驱逐顺序。
- lru 链表。所有已经不再为客户端使用的条目都放在 lru 链表中,该链表按最近使用时间有序,当容量不够用时,会驱逐此链表中最久没有被使用的条目。
- 另外值得一提的是,哈希表中用来处理冲突的链表节点与双向链表中的节点使用的是同一个数据结构(LRUHandle),但在串起来时,用的是 LRUHandle 中不同指针字段。
- 具体实现参见 LRUCache
LRUCache
- LRUCache 实现主要涉及到了四个数据结构:LRUHandle、HandleTable、LRUCache 和 ShardedLRUCache。前三者组织形式如下:
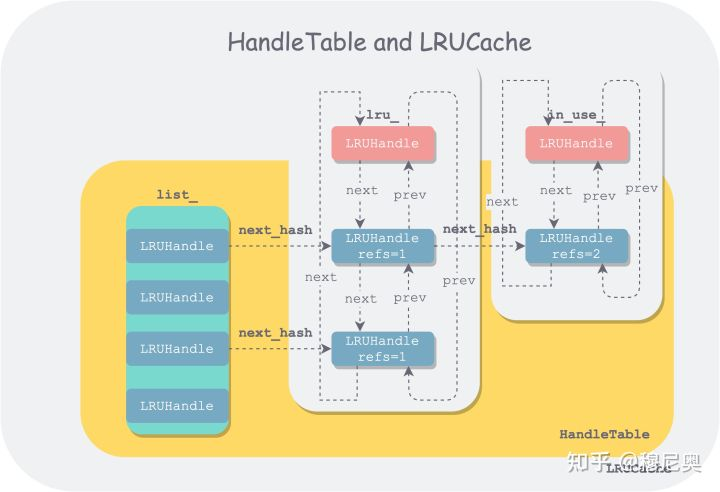
- LRUCache的实现有以下特点:
- 每一个缓存项都保存在一个LRUHandler里;
- 每一个LRUHandler首先被保存在一个哈希表table_里面,支持根据键快速的查找;
- LRUCache里面有两个双向链表lru_和in_use_,每一个LRUHandler可以在两个链表中的一个里,但是不会同时在两个里,也有可能有些LRUHandler被淘汰出缓存了,不在任何链表上
- in_use_保存当前正在被引用的LRUHandler,这个链表主要是为了查询;
- lru_保存没有被使用的LRUHandler,按照访问顺序来保存,lru_.next保存最旧的,lru_.prev保存最新的,需要淘汰缓存时,会从lru_里的next开始淘汰;
- 当一个LRUHandler被使用时,会从lru_移动到in_use_,使用完成后,会从in_use_重新移动到lru_里;
- 每个LRUCache都有一个容量capacity_,表示这个缓存的大小,每次插入一个项时都会指定这个缓存项的大小,更新usage_字段,当usage_超过capacity_时,就淘汰最旧的缓存项,直到低于capacity_。
- 每个 LRUCache 由一把锁 mutex_ 守护。
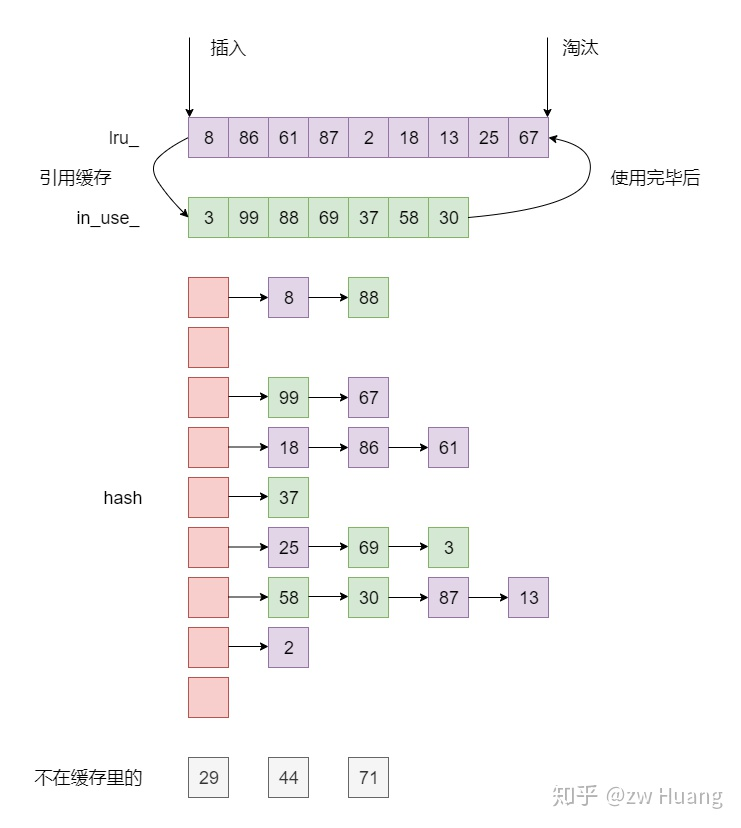
- 插入缓存的流程:
- 生成一个LRUHandler保存缓存的内容,计数为1
- 再将计数加1,表示当前缓存项被当前客户端引用,插入到in_use_链表中;
- 插入时会指定插入项的大小更新usage_字段;
- 插入到哈希表中;
- 如果有相同值旧的缓存项,释放旧项;
- 判断容量是否超标,如果超标,释放最旧的缓存项,直到容量不超标为止。
ShardedLRUCache
- ShardedLRUCache 由一组 LRUCache 组成,每个 LRUCache 作为一个分片,同时是一个加锁的粒度,他们都实现了 Cache 接口。下图画了 4 个分片,代码中是 16 个。
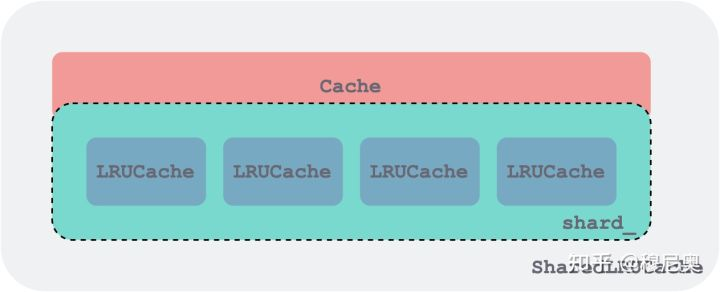
- 为了实现线程安全,LRUCache在做一些操作时,会进行加锁,但是加锁操作会降低并发度,针对这个问题,LevelDB对外提供的实际是一个ShardedLRUCache缓存
- ShardedLRUCache包含一个LRUCache缓存数组,大小是16,根据缓存键的Hash值的高4位进行哈希,将缓存项分布到不同的LRUCache里,这样当并发操作时,很有可能缓存项不在同一个LRUCache里,不会冲突,大大提高了并发度;
- ShardedLRUCache的实现只是简单的将对缓存的操作代理到相应的LRUCache里。
- 引入 SharedLRUCache 的目的在于减小加锁的粒度,提高读写并行度。策略比较简洁—— 利用 key 哈希值的前 kNumShardBits = 4 个 bit 作为分片路由,可以支持 kNumShards = 1 << kNumShardBits 16 个分片。通过 key 的哈希值计算分片索引的函数如下:
- SharedLRUCache 将操作最终都分发到了相应的分区。
缓存使用
- LevelDB里SSTable在内存中是以Table结构存在的,要使用一个SSTable,必须先进行Open操作,会将Index Block和Filter Data都读取到内存里,保存在Table里,但是Data Block依然保存在磁盘上。需要读取数据时,可以将数据放到缓存中,下次再次访问数据时,就可以从缓存里读取。所以缓存有两方面:
- 每个Table结构都要占据一定的内存,被打开的Table放在一个缓存中,缓存一定数量的Table,当数量太多时,有一些Table需要被驱逐出内存,这样当需要再次访问这些Table时需要再次被打开;
- 每个Table的Data Block可以被缓存,这样再次访问相同的数据时,不需要读磁盘
- Table Cache 缓存的实质是对应 Table 的 Index Block 和 Meta Block
- Block Cache 缓存的实质是某个对应的具体的 Data Block
Table 缓存
- SSTable的文件名类似于000005.ldb,前缀部分就是一个file_number,Table就是用这个file_number作为键来缓存的。Table的缓存存储在TableCache类里面。
- Table cache 的具体实现在 table_cache.h 和 table_cache.cc。
- Table cache 的 key 是 SSTable 的 file_number,value 是一个 TableAndFile 对象。
- 查询 Table 步骤:
- 先从缓存里面找,键是file_number,如果找到了,就可以直接返回Table;
- 如果没有找到,需要Open这个SSTable,然后插入到缓存里面;
- 缓存的capacity_大小为支持打开的Table的个数,而每一个缓存项大小为1,这样当缓存的Table个数大于容量时,就会将最旧的Table淘汰。
Data Block缓存
- 每个 Table 打开的时候,都会指定一个cache_id,这是一个单调递增的整数,每个Table都有一个唯一的cache_id。在每一个SSTable里面,每一个Data Block都有一个固定的文件偏移offset。所以每一个Data Block都可以由cache_id和offset来唯一标识,也就是根据这两个值生成一个键,来插入和查找缓存。
- 一个 SSTable 在被打开的时候,会通过 options.block_cache 的 NewId 为其分配一个唯一的 cache_id。
- 每个 data block 保存到 block cache 的 key 为 cache_id + offset。
- 由于 SSTable 是只读的,block 的读取和 block cache 的维护非常简单,具体参考 Table::BlockReader。
- 读取 Block 的步骤:
- 从这个Data Block的索引项出发,根据索引得到offset,然后根据Table得到cache_id,这样就得到了缓存键;
- 在缓存里读取Data Block,如果存在就可以返回;
- 否则从文件里读取Data Block,这里根据选项fill_cache,可以决定是否插入到缓存。
缓存淘汰
- 缓存淘汰提供了两个接口:
- virtual void Prune() // 清理空间,把不被客户端使用到的cache销毁掉
- virtual void Erase(const Slice& key) // 删除单个 Key
- 该函数会先利用哈希索引直接拿到对应的 handle 指针,所以删除直接操作该指针对应的前后指针即可。
- TableCache 的淘汰有两种方式:
- 手动触发:
DBImpl::DeleteObsoleteFiles()调用TableCache::Evict来删除老旧文件对应的 TableCache 缓存,该操作通常发生在 Compaction 的过程中。但本质只删除了 TableCache 的数据项 - 自动触发:
- 当插入一个缓存项,该项之前在缓存中已经存在了对应的 Key 的时候,触发淘汰操作
- 插入一个缓存项,对应的缓存空间容量不足的时候,对应淘汰 LRU 中最长时间没访问的数据(LRU 中的数据如果在队列中又被访问到,会被添加到 in_use 的队列中)
- BlockCache 的淘汰只有一种方式:
- 自动触发,和 TableCache 的自动触发机制一样
- Compaction 操作是如何影响 BlockCache 的?
- Compaction 的本质对应的是老 Table 的删除和新 Table 的创建,当要读取对应的数据的时候根绝 cache_id+offset 来读取,因为 cache_id 是加所自增的唯一 ID,在 Open Table 的时候会为其生成一个 ID
- 所以读取时拿到新的 Table 信息后读取对应的 Block 会根据对应的新的 ID 来作为键去寻找 BlockCache,offset 有一定的机率相同,但 ID 不同。
- 失效了的 BlockCache 其实是无感知的,由 LRUCache 自动淘汰
- Utterance
