MatrixKV
2021-3-2|2023-2-10
DieInADream
type
status
date
slug
summary
tags
category
icon
password
Property
Feb 10, 2023 09:13 AM
其他资料
MatrixKV
PDS-Lab • Updated Dec 14, 2023
matrixkv_record
zkEloHub • Updated Apr 7, 2023


Abstract
- 现有的基于 LSM-tree 的 KV 存储性能表现欠佳,且性能常常无法预测,主要原因就是其严峻的写放大和写停顿的问题(Write Stalls)。实验结果表明:
- 写停顿主要源于 L0-L1 层之间的大量数据的压缩过程
- 写放大会随着 LSM-trees 的深度增加而不断增大
- 利用 NVM 基于 LSM-trees 提出了一种 KV 存储的设计 MatrixKV(包含了多级存储:DRAM-NVM-SSD),设计原则表现为:
- 让 L0-L1 层之间的压缩开销更小从而减少写停顿
- 减小 LSM-tree 的深度来减小写放大
- 核心思想主要表现为以下四点:
- 利用自己提出的 matrix container 在 NVM 上管理 L0 层
- 设计了新的 column compaction 应用到了 L0-L1 的压缩中来减少压缩数据的量
- 增加每一层的宽度(每一层容纳数据的大小)来减少 LSM-tree 的深度
- 引入了 cross-row hint search 来改善读性能
- 和 RocksDB 以及 KVS NoveLSM 对比, 99th 尾延迟降低了 5x 和 1.9x,随机写吞吐量提升了 3.6x 和 2.6x
Introduction
- 为什么引入 NVM?:考虑到随机写操作在流行的 OLTP 工作负载中很常见,不管是突发的还是持续的随机写都是用户很关注的问题,DRAM-SSD 这种存储结构形式就是想利用快速的 DRAM 和持久的 SSD 来提供高性能的数据库访问操作,但是如 cell size、功耗、成本以及 DIMM 槽数量的限制使得不能只通过提升 DRAM 大小来提升性能。因此,在混合存储系统中使用 NVM 成为了现代存储系统的一个新方向。
- 原有的 LSM-tree 存在的问题:在 DRAM-SSD 的存储结构的基础上使用 RocksDB 进行测试,观察实验结果并分析原因:
- 写入停顿会导致应用程序吞吐量周期性地降至几乎为零,从而导致性能的剧烈波动和长尾延迟。写停顿的主要原因是每次 L0-L1 压缩处理的数据量大,合并时会合并 L0 和 L1 的所有数据,但是 L0 无序,合并过程占用较多的 CPU 资源和 SSD 带宽,从而导致写停顿和较高的尾延迟。
- 写入放大(WA) 降低了系统性能和存储设备的耐久性。
关键技术
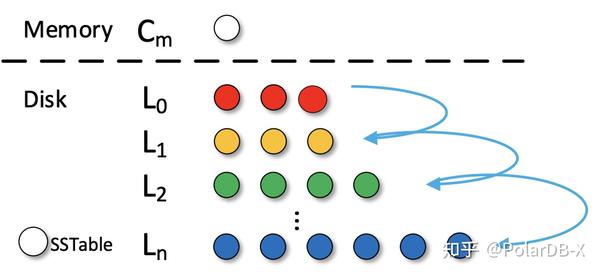
- Matrix container: Matrix Container 通过在 NVM 上使用一个 receiver 和一个 compactor 来管理无序的 L0。
- Receiver 维护来自 DRAM 刷回的 MemTable,一行一个 MemTable。
- Compactor 选择并合并 L0 中的数据子集合到 L1。(选择具有相同键范围的数据),每次压缩一列。
- Column compaction:列压缩是 L0 和 L1 之间的细粒度压缩,每次 压缩一个小的键范围,因为处理的数据量有限,并迅速释放 NVM 中存放的列从而继续接受来自 DRAM 刷回的数据,从而减小写停顿。
- Reducing LSM-tree depth:增大每一层 LSM-tree 的容量来减少层数
- Cross-row hint search:为每个键提供一个指针,用于对 Matrix Container 中的所有键进行逻辑排序,从而加速搜索过程
Background and Motivation
Background
- NVM 的出现:存储介质的发展,PCM、memristors、3D Xpoint、STT-MRAM 等存储介质的发展使得 NVM 成为新的选择。字节寻址、持久化、快速,接近 DRAM 的性能,类似于磁盘的持久性,比 DRAM 更低成本获得更大的容量,比 SSD 更低的读写延迟以及更高的带宽。研究表明 NVM 作为存储设备,使用 PCIe 总线时,只实现了边际的性能改进,浪费了 NVM 的介质带来的高性能,所以很多都将 NVM 作为单级内存使用。最常用的是 DRAM-NVM-SSD 三级存储:
- NVM 有望在未来几年与大容量 SSD 共存
- 与 DRAM 相比,NVM 仍然有 5 倍的低带宽和 3 倍的高读取延迟
- 混合系统平衡了 TCO(the total cost of ownership) 和系统性能。
- 现有 LSM-trees 机制:
- 几个关键点:L0 层无序是为了保证刷回操作的快速执行,磁盘组件上需要进行压缩来减小读操作和扫描的开销。
- 压缩过程大致如下:
- 层的一个 SSTable 和 层的多个 SSTables (具有重叠键范围的)被选作需要压缩的数据
- 中也在该键范围内的 SSTable 会被反选
- 前面两步选择的 SSTable 将被加载到内存进行归并排序
- 新生成的 SSTables 被写回到 层
- 因为 层无序,每一个 SSTable 都有比较宽的键范围,就会来回执行上述步骤中的前两步,就很有可能导致两层中的所有的 SSTable 都被选中用于压缩,导致一个 all-to-all 压缩。
- 读请求的处理,首先查询内存组件中的 MemTable,继续查询磁盘组件的各个层次,但是因为 层无序,即键的范围是重叠的,所以可能该层数据检索时遍历了所有 SSTables

- 现有的 LSM-trees 优化方案:减小写放大、提升内存管理、支持自动调优、使用混合存储结构优化 LSM-tree.其中随机写是最受关注的,因为受压缩的影响较大。对比对象 PebblesDB,SILK,NoveLSM
- 减小写放大:PebblesDB, Lwc-tree, WiscKey, LSM-trie,VTtree, TRIAD。然而,几乎所有这些工作都忽略了性能差异和写停顿。
- 减少写停顿:
- SILK 引入了一个I/O调度器,通过将刷新和压缩延迟到低负载时期、对刷新和较低级别的压缩进行优先级排序以及抢占压缩,可以减轻写暂停对客户端写的影响
- Blsm 提出了一个新的合并调度程序,称为“spring and gear”,以协调多级别的压缩。但该方案只是限制了最大写处理延迟,忽略了排队延迟
- KVell 使磁盘上的 KV 无序,以减少 CPU 计算成本,从而减轻基于 NVMe SSD 的 KV 存储的写停顿,这不适用于具有一般 SSD 的系统
- 引入 NVM 到 LSM 中:SLM-DB,MyNVM,NoveLSM,NVMRocks。
Challenges and Motivations
- 主要表现为两方面:写停顿和写放大。
- 测试结果表明:系统性能经历高峰和低谷,而吞吐量的低谷表现为写停顿。显著的波动表明性能不可预测和不稳定

Write Stalls
- RocksDB 中主要有三种可能的停顿:
- Insert stall:在完成后台刷回之前,如果 Memtable 被填满,所有的插入操作将停顿(内存满)。
- Flush stall: 层有太多的 SSTables 并达到了大小限制,从内存刷回到 的操作将停顿(L0 满)
- Compaction stalls:前面操作有太多待定的压缩数据块 (Compaction 数据量太大,一般不容易出现,取决于 Compaction 策略)
- 所有这些停顿都会对写性能产生 级联影响,并导致写停顿。
- 测试环境:
- RocksDB SSD-based
- 80G data, 16B-4KB key-value, uniform random load
- random write throughput every 10 seconds
- 64MB Memtable/SSTable, 256MB L1, AF=10
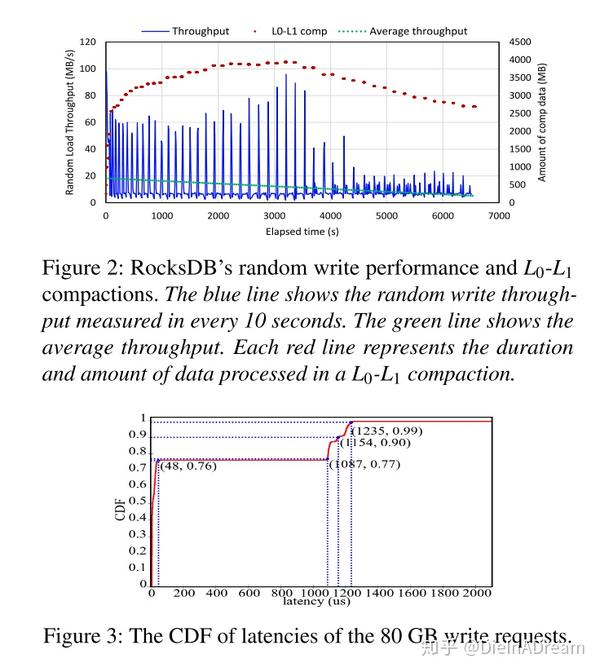
- 通过记录不同 level 的 flush 和 compaction 周期来测试这三种类型的停顿。 压缩的周期与观察到的写停顿近似匹配,如图 2 所示,图中的每一个短红线表示一次 压缩,红线的长度表示压缩的延迟,纵轴对应此次压缩过程中处理的数量。压缩的数据量平均大小为 3.10 GB,大量压缩数据会导致大量的读合并写,占用 CPU 周期和 SSD 带宽,从而阻塞前台请求,使 压缩成为写停顿的主要原因。(从图中看的意思就是 压缩的时候出现了 stall)
- 写停顿不仅导致系统吞吐量低,而且还导致了高写延迟,从而导致长尾延迟问题。CDF 累积分布函数如图所示,76% 的写请求延迟低于 48 微秒,但是尾延迟达到了 1ms,高延迟会显著降低用户体验的质量,特别是对于延迟关键型应用程序

Write Amplification
- 系统吞吐量随着数据集大小的增加而降低。写放大(WA)定义为写入存储设备的数据量与用户写入的数据量之间的比率。由于相邻 Level 的大小从低到高以放大倍数(AF = 10)呈指数增长,所以从 到 的压缩可能会导致平均 AF 倍的写放大,数据集的增长会增加 LSM 树的深度,也会增加总体 WA。增加的 WA 消耗更多的存储带宽,与刷新操作竞争,并最终降低应用程序吞吐量。因此,系统吞吐量随着 LSM 树深度的增加而降低。
NoveLSM
- 设计思想主要表现为:
- 采用 NVM 替代 DRAM,从而增加可以存储的 Memtable 和 Immutable Memtable 的容量
- 允许 NVM 上的 Memtable 被直接更新从而减少压缩
- 然而,这些设计选择只是推迟了写停顿,当数据集大小达到了 NVM Memtable 的容量,还是会产生 flush stall,(这里有个疑问,为啥是 flush stall,不应该是 insert stall 吗?)NVM 中扩大的 memtable 被刷新到 ,并显著增加了 压缩中的数据量,导致更严重的写停顿。
- 使用 8GB 的 NVM 和 80GB 的数据集测试了 NoveLSM,测试结果如图所示:相比于 RocksDB 整体 load 时间下降了 1.7 倍,但是写停顿的周期变得更长,主要是因为 压缩中的数据量较大,如图所示超过了 15GB,和图二中 RocksDB 的数据量对比 4.86x。当 压缩开始就会产生写停顿,在压缩开始之前可能还要等待更高级别或者更高优先级的压缩完成,如图中的灰色短线所示,压缩完成后性能再次提升。显然,NoveLSM 加剧了写停顿。

Summary
- 从上述分析中我们不难看出造成写停顿的主要原因是 - 压缩过程中的数据量太大,造成写放大系数较大的原因是 LSM-trees 的深度较大。正是两者的共同作用使得系统吞吐量较低并增大了尾延迟。
- NoveLSM 试图解决这些问题时却加剧了写停顿,基于以上挑战,我们提出了 MatrixKV,致力于通过巧妙地使用 NVM 来提供一个稳定的低延迟的 KV 存储。
MatrixKV Design
- 四个关键技术:
- the matrix container in NVMs to manage the L0 of LSM-trees
- column compactions for L0 and L1
- reducing LSM-tree levels
- the cross-row hint search

Matrix Container
- NoverLSM 使用 NVM 来增大 MemTable 的大小,但是因为有了更大的 L0 层(刷回 L0 的数据变大)加剧了写停顿,并未解决瓶颈。因此为了减少写停顿,需要遵循的基本原则就是减少 - 单次压缩过程中的数据量或粒度。基于这样的原则,MatrixKV 从 SSD 上将 L0 层提升到了 NVM,并重新组织 L0 到 matrix container 中,想要充分利用 NVM 的字节寻址和快速的随机访问。matrix container 是在 NVM 上的 L0 的数据管理结构,如图所示,主要由 Receiver 和 Compactor 组成。

- Receiver
- Receiver 接收从 DRAM 刷回的 MemTables,每一个 Memtable 被序列化成 Receiver 中一个单独的行,称为 RowTable(NoveLSM 中对于 NVM 上的数据结构没有进行序列化的操作,而此处则序列化成了 RowTable 指定格式)。在 Matrix Container 中 RowTable 按行排列,有对应的序列编号,从 0 到 n,Receiver 初始容量为一个 RowTable,当 Receiver 的大小达到阈值时,比如 Matrix Container 的百分之六十,并且 Compactor 为空的时候,Receiver 将停止接受 flush 的 MemTables 并转变为 Compactor。与此同时,会创建一个新的 Receiver 用于接受 Flushed Memtables,在整个逻辑转换过程中不会发生任何数据迁移。(Receiver 也采用了类似 Mutable 和 Immutable 的 ping-pong buffer 的模式)
- RowTable:由数据和元数据组成,为了构造 RowTable,我们 必须首先序列化来自 Immutable Memtable 的 KV 对并进行排序,然后存储到到对应的数据区。然后使用一个有序的数组为所有 KV 对构建元数据,包含对应的页号,在页内的偏移,一个前置指针 。
- 在 RowTable 中查找 KV,首先进行二分查找找到对应的目标 Key 和对应的页号、偏移量。
- 每个元素的 forward pointer 是用于 cross-row hint 搜索的,从而提升读性能。后面章节会讨论。
- 和传统的 LSM-trees 中的 SSTable 进行对比,SSTable 是以块为单位进行组织的,RowTable 是以 NVM 页为单位进行组织的,除此以外就是元数据的组织方式上略有不同,但构建 SSTable 和 RowTable 的开销时接近的。
- 每个键值对数据和 SST 一样,主要关注元数据,为每个数据维护了 key, offset, page, 以及 forward pointer (元数据维护的开销仿佛不小。。LevelDB 本质只是给每个 Block 维护了元数据,其实就是一个 Block 一个 Filter,然后一个 SST 一个 index block)
- 延伸出了两种方案的对比:
- SST 的多层检索 footer→index→meta index→meta(filter)→data 及其空间开销
- RowTable的快速检索 Metadata→page 及其空间开销

- Compactor:用于以较细的粒度选择和合并 SSD 中从 到 的数据。利用 NVM 字节寻址的特性以及我们设计的 RowTable 可以实现开销更小的压缩。合并特定的键范围从 到 上的 SSTables 子集,而不需要合并所有 和所有。我们称之为 Column Compaction。
- 在 Compactor 中,KV 对由逻辑上的列来组织管理,一列就是一个具有一定数量的 Key 的子集,也就是 Column Compaction 的基本单元。具体而言,来自不同 RowTables 的 KV 键值对在一个列对应的键范围内形成了一个逻辑上的列。
- 这些位于一列里的 KV 对的数量即为一个列的大小,因此一个列的大小不是固定的,但是会有一个由 Column Compaction 控制的阈值大小。

- Space Management:在一个列的数据被压缩之后,对应的占据的 NVM 的空间将会被释放。我们使用了页面管理算法来管理这些空闲的空间。由于列压缩会旋转键范围,因此每个行表 RowTable 最多只分段一个页面(*这里没太懂啥意思**)。列压缩后完全释放的 NVM 页面将作为一组页面大小的单元添加到空闲列表中。为了在 Receiver 中存储传入的 RowTable,我们应用空闲列表中的空闲页面。
- 8GB 的 matrix container 包含 个 4K 大小的页,每一个页由页号(无符号整数)标识,为每个列表元素添加 8 字节的指针,每个页面的元数据大小即为 12 字节。因此 NVM 上空闲列表元数据最多占据 24KB。
- 值得注意的是,在矩阵容器中,当列在压缩器中被压缩时,接收端可以继续同时接收从DRAM中刷新的MemTables。通过每次释放一列的NVM空间,MatrixKV将整个L0与所有L1合并,从而结束了写入停滞
Column Compaction
- 该压缩过程是指 到 的一种细粒度压缩方式。因此减少了 到 压缩过程中的数据量,从而减少写停顿。该压缩过程大致如下:
- MatrixKV 将 的键空间分隔为多个连续的键范围:因为 的 SSTables 有序,每一个 SSTable 都有对应的最小和最大键,所有的 SSTables 的最小键和最大键形成一个有序的键列表,每两个相邻的键代表一个键范围,就能得到多个连续的键范围。
- Column Compaction 从上述步骤的第一个键范围开始,即选择一个 中的键范围作为要压缩的键范围。
- 在 Compactor 中,对应压缩键范围的 KV 对被并发地从多个 Rows 中选出来。假设由 N 个 RowTables,K 个线程用于并行地取对应范围的键,那么每个线程负责 N/K 个RowTables,我们为了保证足够的并发访问,用 8 个线程去 NVM 上操作。
- 如果取到的数据个数没有达到压缩的阈值下界,那么将会加入第二个键范围,对应的 K 个线程将继续在 N 个 Row 中寻找对应的 KV 对,直到取到的键值对数目位于压缩的阈值下界和上界之间时 (即 到 之间)。这两个边界值保证了 Column Compaction 合理的开销
- 上述步骤选择出的 KV 对在 Compactor 中形成一个逻辑的列
- 列中的数据和对应的具有重叠键范围的 层的 SSTables 在内存中进行合并
- 最终,合并后的 SSTables 被写回 层
- Column Compaction 继续执行,选择下一个键范围,下一列。Column Compaction 选择键范围将形成一个环,旋转一直执行,从而保证平衡。
- 如图所示:首先选择了 0-3 的 SSTable 范围,然后搜索 RowTable 元数据找到对应的键,个数低于下界,即不足以执行一次压缩,那么继续选择一个键范围,比如 3-5,那么合并之后就是 0-5,如果还是未到下界,继续扩大,再选择 5-8,此时达到阈值 10,最终选择 0-8。此时就形成了逻辑上的一列。然后和 L1 上的前面两个 SST 进行合并。
- 通用情况下,就是首先从 L1 中选择一个具体的键范围,然后在 Compactor 中压缩对应重叠的列,相比于原有 LSM 的 all2all 的压缩逻辑,column compaction 压缩的范围更小,数据量也有限,因此,细粒度列压缩缩短了压缩持续时间,从而减少了写延迟。

Reducing LSM-tree Depth
- 传统的 LSM-trees 对应的 AF 一般为 10,其深度会随着数据量的增长而不断增大,写放大系数对应的可以表示为 ,其中 N 为 LSM-trees 的层级数。因此 Matrix 的另一个设计思路就是通过减小 LSM-tree 的深度来减小写放大。MatrixKV 通过固定比例增加每一层的大小限制,使相邻层的 AF 保持不变来减少 LSM-tree 的层数。(通俗地讲就是由一个高高的瘦子变成矮矮的胖子)
- 但是这样纯粹的单层扩大带来了两个负面影响:
- 扩大后的 与 有更多的重叠键范围,那么压缩过程中的数据量将增大,不仅仅会增加压缩的开销还会延长写停顿的时间。(为啥其他层没有这个问题,是因为其他层次都是选择性的压缩,不是像 L0-L1 的 ALL2ALL)
- 遍历更大的 会降低查询操作的效率(虽然是 NVM 上查询,但还是因为数据变多了,效率一定程度上下降了)。
- 通过使用 Column Compaction 能够较好地解决第一个负面影响,因为该压缩方式不会受到每一层的数据容量的影响
- Matrix 提出了 cross-row hint search 来改善增大单层容量操作带来的查询开销(也就是解决第二个问题)
Cross-row Hint Search
- 在 MatrixKV 的 ,每一个 RowTable 是有序的,不同的 RowTables 的键范围可能重叠。为每一个 table 构建布隆过滤器是减小查询开销的一个可能的方案,然而会引入构建布隆过滤器的开销而且不支持 range scan。为了提供更好的读和 scan 性能,我们构建了 cross-row hint searches
- Constructing cross-row hints:在 RowTable 的结构中我们为每一个元素添加了前置指针。RowTable i 中的 key x,对应的前置指针指向了 RowTable i-1 的 key y,y 是第一个不小于 x 的 key(大于等于)。这些前向指针提供了在不同行中对所有键进行逻辑排序的提示,类似于分层级联。因为每个前置指针只记录上一个行表的数组索引,所以只占据 4bytes,因此开销很低。(疑问:存储开销是很低,但是具体为每一个元素维护指针不是应该还挺耗时的吗?所以是序列化的时候就给维护好?因为本身去构建这个指针的时候是需要进行查询的,根据其大小关系来决定指针的指向,所以构建这个前向指针的开销到底是啥样的?)
- Search process in the matrix container:一个查询操作从最近最新的 RowTable i 开始,如果目标 key 不在对应的键范围内,则相应地去检索 RowTable i-1。在 RowTable 内部执行二分查找。使用前向指针,我们可以缩小在前面的 RowTables 中的搜索范围。因此查询和 scan 操作将无须遍历所有的 tables。该方式通过显著减少查询操作对应的 table 和元素的数量来提升了整体的读效率。
- 如图所示,假设我们检索 k=12 的 key,首先二分查找 RowTable 3,得到一个范围 10-23,然后根据前置指针 hint 找到 RowTable 2 中的 13-30,因为不包含 12,此时需要把 13 之前的 8 给纳入进来,变成 8-13-30。再进行二分查找,没找到对应的 key,8-13, 移动到 RowTable 1, 9-10-13,二分查找 10-13,无对应的 key,继续看 RowTable 0,11-12-14,二分查找找到了 12.

问题:为什么要执行二分而不是直接顺着指针的方向直接一个个去找?
- 主要是为了避免一种特殊的情况,即其中一个 Table 内相邻的两个元素数据相差较大,即数据密度相对较低,这时候如果使用单个指针顺着链路去找的话可能出现链路很长的情况,而如果表密度比较大的话,也就是说数据表相对紧凑,那么可以直接使用指针链式搜索可能访问的元素更少、
- 或许可以在这个策略上做一个量化分析,然后做 trade-off。、
- 这里也不能直接用整个表的数据密度来决策使用哪种搜索方式,还是需要考虑当前要搜索的键对应的在表中的包含该键的范围的大小情况来决定。
Implementation
- MatrixKV 通过使用 PMDK 库来访问 NVMs,使用 POSIX API 来访问 SSDs。
- Write:
- 来自用户的写请求首先插入了一个 WAL 日志到 NVMs 以保证崩溃一致性(NVM存放WAL)
- 数据在 DRAM 中被批量处理,形成 MemTable 和 Immutable Memtable
- (Change)Immutable Memtable 被刷入到 NVM 并以 RowTable 的形式保存在 matrix container 的 receiver 中
- (Change)当 RowTables 的数量到达了大小限制,例如 matrix container 的百分之六十,且 compactor 为空,receiver 将变成 compactor
- (Change)Compactor 中的数据将和 SSTable 数据以 Column Compaction 的形式进行压缩,同时新的 receiver 将继续接受刷回的 Memtables
- SSDs 上的压缩还是和原有的 RocksDB 保持一致
- Read:同 RocksDB 的读操作处理方式大致相同,顺序变为 DRAM > NVM > SSD。在 NVMs 中,cross-row hint 搜索有助于更快地在 L0 的不同 RowTables 之间进行搜索。通过在不同的存储设备中并发地搜索,可以进一步提高读取性能(类似于 Novelsm)。
- Consistency:NVM 中的数据结构必须避免由系统故障引起的不一致性。在 MatrixKV 中,对 NVM 的写或更新操作只发生在两个阶段,flush 和 column compaction。
- 对于 flush 操作(DRAM 到 NVM),如果在写 RowTable 的过程中发生了错误,MatrixKV 可以重新处理被记录在 WAL 中的事务
- 对于 Column Compaction 操作,为了实现一致性和可靠性的低开销,Matrix 采用了 RocksDB 的版本机制,使用一个 mainfest 文件记录数据库的状态,compaction 的操作会被持久化到 mainfest 文件中,作为一个版本的变化。如果系统发生了故障,则使用版本号恢复到最近的一个一致的状态。MatrixKV 会添加 RowTables 的状态到 mainfest 文件中,例如第一个 key 对应的偏移,key 的数量,文件的大小,元数据的大小等。MatrixKV 使用延迟删除来保证在一个一致的新版本完成之前,由于列压缩而失效的陈旧列不会被删除。
Evaluation
测试环境
- 硬件:
- 2 Genuine Intel(R) 2.20GHz 24-core processors
- 32 GB of memory
- 800 GB Intel SSDSC2BB800G7 SSD
- 256 GB NVMs of two 128 GB Intel Optane DC PMM

- 软件:
- The kernel version is 64-bit Linux 4.13.9
- OS: Fedora 27
对照组
- RocksDB (including RocksDB-SSD and RocksDB-L0-NVM(8G) )
- RocksDB-SSD: DRAM-SSD hierarchy
- RocksDB-L0-NVM(8G):DRAM-NVM-SSD
- NoveLSM 8GB NVM store two MemTables (2*4 GB).
- MatrixKV 8 GB L0, SSD L1 8GB
- PebblesDB DRAM-NVM
- SILK DRAM-NVM
其他配置
- RocksDB:
- 64 MB MemTables/SSTables
- 256 MB L1 size
- AF of 10
- The default key-value sizes are 16 bytes and 4 KB
- 强制将 80GB 测试数据的大部分刷新到 SSD 盘
负载
- db_bench: the micro-benchmark released with RocksDB.
- YCSB macro-benchmarks
测试结果
db_bench 写性能
80 GB in a uniformly distributed
- 随机写
- RocksDB-SSD 和 RocksDB-L0-NVM 之间的对比表明:通过将 L0 放置在 NVM 上带来了大约 65% 的提升
- Matrix 相比 RocksDB-L0-NVM 和 NoveLSM 吞吐量在所有的 value 大小都有提升,相比于 RocksDB-L0-NVM 提升了大约 1.86x 到 3.61x,相比于 NoveLSM 提升了 1.72x 到 2.61x
- 顺序写
- 因为顺序写没有导致压缩,所以四种存储的顺序写吞吐量都要比随机写的吞吐量要高。
- RocksDB-SSD 性能更好是因为其他三种存储引擎都使用了 NVM,就多了一次 NVM 到 SSD 上的数据迁移开销。
- MatrixKV 优于 NoveLSM 是因为 维护 RowTable 的开销比在 NoveLSM 上的大的跳表更新的开销小。
db_bench 读性能
- 通过从随机加载的 80GB 数据库中读取 100 万个 KV 项来评估随机/顺序读性能。为了获得不受压缩影响的读性能,我们在树达到良好平衡后开始读测试。
- 因为 NVM 中只保存了数据量百分之十的数据,所以还是 SSD 的读性能占据了更大的比重。四种方案总体表现接近,MatrixKV 优化之后并没有造成读性能降级甚至在顺序读上有一定的提升:因为 cross-row hint 搜索减少了大 L0 的检索开销,还拥有更小的层数,进一步使得查询的开销变小。

YCSB
我们首先编写一个80gb的数据集和4KB的值用于加载,然后分别用100万KV的项目评估工作负载A-F
- 结果
- MatrixKV 在写密集的负载下提升效果明显
- MatrixKV 在读密集的负载下保持了平均水平
- MatrixKV 和 NoveLSM 在负载 D 下表现得最好是因为 latest 的分布,使得在 NVM 中就能命中很多数据,MatrixKV 得益于 cross-hint-search,但是 MatrixKV 不如 NoveLSM

- Tail latency
- YCSB-A workload, setting request arrival rate at around 20K requests/s
- 通过减少写停顿和写放大,MatrixKV 极大降低了尾延迟并提升了用户服务质量。

性能分析
写停顿
- MatrixKV 使用了更少的时间处理对应的负载,因为随机写吞吐量更高
- RocksDB 和 NoveLSM 都有严重的由于 到 之间的压缩造成的写停顿问题
- NoveLSM 写停顿更严重是因为 L0 维护了更大的来自 NVM 刷回的 Memtable。
- RocksDB-L0-NVM 也是因为 L0 变大导致的写停顿更严重。
- MatrixKV 相比之下实现了最稳定的性能,因为 column compaction strategy (仿佛也没多稳定,只是确实没 stall,后期有个很严重的下降)

写放大
- MatrixKV 的写放大系数更小,因为降低了 LSM Tree 的深度,减少了 compaction 的数量。

MatrixKV Enabling Techniques
- Column compaction
- Column compaction 的效率对比,我们在相同的 80GB 随机写实验中记录了4个KV存储所涉及的数据量和每次L0-L1压缩的持续时间。纵轴为压缩的数据量,X轴为每次持续的时间
- MatrixKV 大概进行了 467 次,每个 0.33GB,写入了 153GB 数据
- RocksDB-SSD 处理了 52 次压缩,平均每次大小 3.1GB,写入了 157GB 数据
- MatrixKV 处理更细粒度的 L0 - L1 压缩,其中每个压缩具有最少的数据量和最短的压缩持续时间,因此,列压缩对前台请求的影响很小,并最终显著减少了写暂停。NoveLSM实际上加剧了写停滞,因为从NVM中刷新的MemTables增大了每次L0-L1压缩时处理的数据量。
- NoveLSM 多量少次
- MatrixKV 少量多次

- Overall compaction efficiency
- 通过记录随机写实验中每次压缩的数据量,我们进一步记录了四个KV存储的总体压缩行为
- Overall compaction efficiency:
- MatrixKV 压缩次数最少,因为树的层级降低
- MatrixKV 中的所有压缩处理的数据量相近,因为我们减少了 L0-L1 上的压缩数据量,而没有增加其他级别上的压缩数据量。
- NoveLSM and RocksDB-L0-NVM 比 RocksDB-SSD 压缩次数少的原因是
- NoveLSM 使用了比较大的 Memtable 来处理写请求,吸收了一部分的 update 请求
- RocksDB-L0-NVM 在 NVM 上存放了 8GB L0 数据,存储了更多的数据
- NoveLSM 和 RocksDB 大量的压缩数据来自于 L0-L1 压缩。

- Reducing LSM-tree depth
- 为了评价 lsm-tree 的扁平化技术,我们改变了 RocksDB 和 MatrixKV 的 Level 大小。(RocksDB L1 大小默认 256MB,设置为 8GB,AF = 10,层级从 5 个减少到 3 个)
- Reducing LSM-tree depth:RocsksDB 和 MatrixKV 随着单层容量的增加都减小了写放大,但是对性能的影响有所不同,RocksDB 随着单层的增大性能反而降低,因为增大了 到 压缩的数据量。MatrixKV 使用了独立的压缩策略不受大小变化的影响才得以实现更高的性能。RocksDB-L0-NVM 比 RocksDB-SSD 好一点是因为吧 L0 放置到了 NVM 上。
- 把MatrixKV 的 Level 大小调整回 256MB 也显示出了解决 write stall 之后带来的性能的显著提升。

- Cross-row hint search
- 为了评估交叉提示搜索技术,我们首先随机编写一个 8GB、4KB 值大小的数据集来填充MatrixKV 和 Rocksb-L0-NVM 的 NVM 中的 L0。然后以均匀随机顺序从 NVM 中搜索 100 万个 KV 项。该实验使得 NVM 能够容纳 100% 的数据集,充分反映了跨行提示搜索的效率。
- rocksdb-L0-nvm 和 MatrixKV 的随机读吞吐量分别为9 MB/s和157.9 MB/s。因此,与简单地在 nvm 中放置 L0 相比,跨行提示搜索的读效率提高了17.5倍。
Extended Comparisons on NVMs
- MatrixKV 不仅仅是因为 NVM 的引入使得性能变得很好,还有设计思路和方案的加持。故和其他基于 NVM 魔改后的方案进行了对比:(魔改的方式就是把内存组件以外的其他组件放在 NVM 上)
- 通过对比发现,MatrixKV 的方案是很适合 NVM 的,相比于其他如 PebblesDB 把 NVM 作为块设备的方案。
- 吞吐量(随机写 80GB 数据):在所有KV存储中,MatrixKV的性能最好。结果表明,MatrixKV的使能技术适用于NVM器件。使用NVM作为快速块设备,PebblesDB没有表现出比RocksDB更大的改进。SILK比RocksDB稍差一些,因为它的设计策略相对于密集的写操作而言优势有限。(SILK 主要还是解决的是延迟相关的问题)
- 尾部延迟用YCSB-A工作负载评估,如所示。由于NVM具有比ssd更好的性能,所以我们可以加速客户机的请求(60K个请求/秒)。表3中的测试结果显示,对于 NVM 的持久存储,大多数KV存储提供了足够的尾部延迟。但是,MatrixKV仍然实现了最短的尾部延迟。

Conclusion
- 提出了基于 LSM-trees 的稳定的、低延迟的 KV 存储方案
- 使用了多级存储结构 DRAM-NVM-SSD
- 在 NVM 上设计实现了 matrix container 来管理 $L_0$ 层,并采用适当的粒度进行 Column Compaction 来减小写停顿
- 通过增大每一层的容量来减小树的高度,从而减小写放大
- 使用 cross-hint search 来保证原有的读性能
Extension
- TPDS’22 TriangleKV: Reducing Write Stalls and Write Amplification in LSM-tree Based KV Stores with Triangle Container in NVM
概览
- 在 MatrixKV 的 Motivation 的基础上提出了 TriangleKV,指出了使用 NVM 管理 Memtable 和 Immutable Memtable 存在的问题
- NVM 始终比 DRAM 慢好几倍,使用 NVM 存储 Memtable 和 Immutable Memtable 都会导致读写性能的下降
- 往 Memtable 插入数据需要查询跳表,引入多个指针的修改操作,对于 NVM 来说开销也很大

- MatrixKV 在 NVM 上管理 L0,优势主要在于
- NVM 比 SSD 快,刷回可以快速执行,刷回也不会和其他 SSD 上的 Compaction 操作竞争 SSD 带宽
- NVM 是字节寻址的,L0-L1 的压缩可以以一个非常细粒度执行,空间可以在 Compaction 执行后立即释放,在 SSD 上必须等整个文件被压缩之后才删除
- MatrixKV 的 PM 上有两个主要的角色:Receiver 和 Compactor
- Receiver 接受内存中的 Immutable Memtable 的刷回,达到大小限制之后转换成 Compactor,然后生成一个新的 Receiver
- Compactor 中的数据会被压缩到 SSD 上的 L1,使用一个细粒度的 Column Compaction 策略,每次只会压缩数据的一个子集,减小压缩开销,从而减小写停顿
- 作者指出了 MatrixKV 存在的问题:
- Column Compaction 只会在 Compactor 中执行,Receiver 中对应重叠范围的数据却不能参与 Compaction 过程。如下图所示的 Compactor 的 a-c 压缩到了 L1,但是 Receiver 的相同键范围仍然还在 L0,当 Receiver 转换成 Compactor 的时候,范围 a-c 再次被 Compacted,意味着范围 a-c 在 L1 上要写两次,导致额外的写放大。
- 这里的写放大的理解:原本 L1 上的属于范围 a-c 的数据在第一次 Compaction 的时候就已经执行了一次归并排序,后续 Receiver 的 a-c 再触发了一次,那么对于 SSD 上 L1 的 a-c 的数据而言,就执行了两次读后写。
- 作者提出了 Triangle Container,以及新的 Compaction 方案 Right-angle Side Compaction

Triangle Container
- 减小写停顿的核心思路就是减小 L0-L1 的压缩粒度,减小对于 SSD 的 I/O
- TriangleKV 也是直接把 L0 从 SSD 上放到 NVM 上,组织成一个三角形容器来利用 NVM 的字节寻址和高速随机访问
- Immutable Memtable 从 DRAM 中刷回到 NVM 上,以一个 Row 的形式,一个 RowTable 也就对应一个 Memtable,RowTables 作为三角形数据结构的底边堆叠,其序号递增,即从 0 到 n。三角形数据结构的大小从一个 RowTable 开始。当三角形数据结构的大小达到其大小限制(例如NVM总量的60%)时,子范围合并操作从 L0-L1 开始。参与每个子范围合并操作的是三角形数据结构的垂直直角边的数据,即最长时间未被合并的子键值范围。L0-L1 的子范围合并操作与 DRAM 的flush 操作同步执行,因此 NVM 内部的数据结构保持在三角平衡状态。

- 下图展示了一个三角数据结构动态变化的例子。
- 此时有六个表,假设总的键空间是 a-f,正在合并的范围是 a。L0-L1 合并了范围 a 的数据以后,该范围的所有数据写到了 SSD,因此,每个 RowTable 就不再包含键范围 a,如图 b 所示。当 DRAM 刷回一个新的 Memtable,也就是对应的 RowTable 6,对应的范围是 a-f,这时候只有 RowTable 包含 a,L0-L1 的子范围合并就轮到了 范围 b 的数据开始执行,所以在范围 b 中的数据将再被合并到 L1
- 每次压缩的就是一个子范围,该子范围的选择就是一个轮询,轮询的本质就是选择了最长时间没被选择的数据来操作。压缩和 flush 之间没太多干扰,因为是轮询,每次都检查对应的所有表有没有这个子范围的数据就行了,有的话就执行 compaction。
- 本质和 MatrixKV 的区别就在于只用了一个组件,类似于 L0。然后选择执行 Compaction 的子范围的逻辑轮询执行。本质是对 L1 上的数据范围进行的轮询

- 空间管理方面:执行了子范围的压缩之后,使用页面管理算法来管理,即对应的直角边上的数据压缩之后,释放对应的页面,然后用一个空闲队列来追溯。新 flush 来的 RowTable 就用空闲队列中的页面来存。
Right-angle Side Compaction
- 压缩和 MatrixKV 的逻辑类似。选择了一个范围之后,并发地从 RowTable 上去读取,k 个线程读取 N 个 RowTables。作者设置 k=8,

- Utterance
